


This week’s research review features new advanced LLMs, including technical reports on the DeepSeek-V3 and Qwen2.5 families of models, the latest updates to the original BERT encoder model, and improvements to AI model inference by directly iterating over the latent space. Masu.
DeepSeek-V3 Technical Report
Qwen2.5 Technical Report
ModernBERT: A fast, memory-efficient, long-context bidirectional encoder for fine-tuning and inference.
Coconut: Training an LLM for reasoning in continuous latent spaces.
We now have a 100% open source LLM that outperforms GPT 4o and Claude 3.5 Sonnet on many benchmarks. DeepSeek-V3 modela powerful Mix of Experts (MoE) language model with a total of 671B parameters and 37B enabled for each token. DeepSeek team shared the model hug face It is licensed under the generous open MIT license, and model details are also provided in “.DeepSeek-V3 Technical Report”
DeepSeek MoE architecture is a fine-grained MoE. 1 shared expert and 256 experts dispatched, 8 active routing experts per token. The architecture also includes multihead latent attention with low-rank join compression on attention keys and values. Also, Multi-token predictionwhich helps in speculative decoding and better use of training data.

Deepseek-V3 was trained with 14.8 trillion training tokens, used 2788K H800 GPU hours, and cost only $5.6 million. This cost-effective training of DeepSeek-V3 is due to its fine-grained MoE architecture, use of FP8 mixed precision in training, and adjusting and expanding the context length during training.
They overcame communication bottlenecks in training large-scale MoE models through co-design of algorithms, frameworks, and hardware and achieved efficient use of computation in training. A two-step context length expansion first extended the context from 4k tokens to 32k tokens, and then to 128k tokens. The combination of these optimizations results in very high training efficiency and a 10x cost reduction compared to Llama, Claude, and similar AI models.
Post-training During training, we used SFT and RL to extract DeepSeek-R1’s inference capabilities and its inference model to suit human preferences and enhance its inference and mathematics abilities. Multi-token prediction (MTP) enables speculative decoding to enhance model performance and speed up inference.
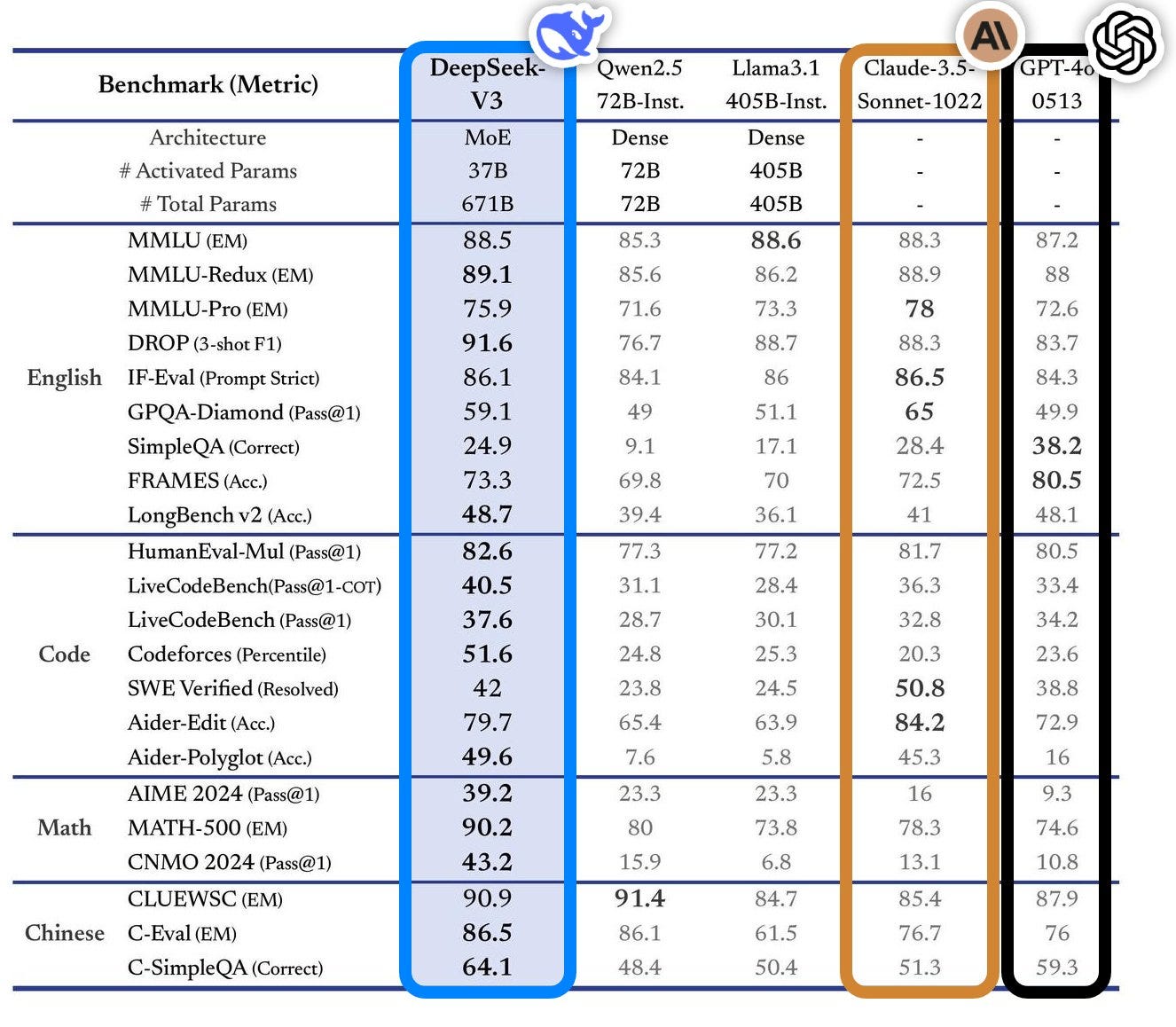
DeepSeek-V3 shows very good benchmarks against MoE LLM with active parameters of only 37B. 88.5 for MMLU, 59.1 for GPQA, 75.9 for MMLU-Pro, 90.2 for MATH, 51.6 for CodeForces, etc. DeepSeek-V3 is the most powerful open source model currently available, delivering performance comparable to leading closed source models such as GPT-4o and Claude-3.5-Sonnet.
LLM’s Qwen 2.5 family was released in SeptemberSince then, Alibaba Qwen team has released the following helpful updates: Qwen-2.5 Coder 32B Model, Expanding the context of 1 million tokens support, and Qwen QwQ, Inference AI Model Quen 32B base. This week they released QvQ, vision inference model Built on Qwen2-VL-72B. With this series of releases, Qwen has established itself as a leading LLM family with some of the best AI models for coding, inference, and local use.
Alibaba Qwen team published: Qwen2.5 Technical Report Learn more about this open weight LLM family. The Qwen2.5 family consists of several open weight-based and instruction-tuned models ranging from 0.5B to 72B parameters. Additionally, two unique Mixture-of-Experts (MoE) models are available: Qwen2.5-Turbo and Qwen2.5-Plus. The flagship open weight model, Qwen2.5-72B-Instruct, matches the performance of Llama-3-405B-Instruct.
Some of Qwen2.5’s main features and improvements from previous versions:
Qwen2.5 LLM leverages grouped query attention (GQA), SwiGLU activation, rotary position embedding (RoPE), QKV bias, and RMSNorm to maintain a transformer-based decoder architecture. Tokenization uses byte-level byte-pair encoding (BBPE) with an expanded set of control tokens.
The Qwen team expanded the pre-training dataset to 18 trillion tokens by incorporating more diverse and high-quality data. Pre-training included advanced data filtering, strategic data mixing with a focus on knowledge, code, and math, and lengthy context training.
Post-training For training, we combined complex supervised fine-tuning (SFT) with over 1 million samples and multi-stage reinforcement learning (DPO, then GRPO). The two-stage reinforcement learning involved offline learning for complex inference and online learning for nuanced output quality.
The model leverages YARN and Dual Chunk Attention (DCA) to scale context length, up to 1 million tokens on Qwen2.5-Turbo.
These training advances have improved human preference tuning, enhanced long text generation, and improved structured data analysis.
Evaluations have demonstrated best-in-class performance in terms of language understanding, mathematics, coding, and human preference adjustment, and the report also highlights Qwen2.5’s long context capabilities. For example, Qwen2.5-Turbo in particular achieved 100% accuracy on a 1M token passkey retrieval task. Qwen2.5 also served as the foundation for the latest and greatest specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models such as QvQ.
While most proprietary AI model vendors keep their technical details secret, the Qwen and DeepSeek teams are refreshingly open about their models and their details in their respective technical reports. This openness helps the AI industry advance, while also showing that open AI models are fast followers of leading AI models.
The original BERT model (BERT stands for Bidirectional Encoder Representations from Transformers) is an encoder-specific model developed to learn linguistic representations from unlabeled text by jointly conditioning the left and right contexts of all layers. Transformers model. The BERT model has many applications in information retrieval and language processing, including use in semantic search, classification, and RAG applications, and has also paved the way for the development of (decoder-specific) LLMs.
author of Smarter, better, faster, longer: a modern bidirectional encoder for fast, memory-efficient, long-context fine-tuning and inference Since this architecture currently has many applications, we decided to update the BERT model with the ModernBERT model.
In this paper, we present ModernBERT, which brings modern model optimizations to encoder-only models and shows significant Pareto improvements over older encoders.
ModernBERT is pre-trained with 2 trillion tokens, incorporates a diverse dataset with code, and boasts a native 8192 sequence length. It leverages recent advances in transformer architectures, such as GeGLU activation, rotational position embedding (RoPE), and alternating local and global attention mechanisms. We used full model unpadding to improve efficiency and avoid wasted computations on padding tokens, combined with Flash attention to optimize kernel usage.
ModernBERT comes in two variants: “base” (149M parameters) and “large” (395M parameters).
The latest BERT models show state-of-the-art results in a large evaluation pool that includes diverse classification tasks and both single-vector and multi-vector searches in a variety of domains (including code).
For natural language understanding (NLU) on the GLUE benchmark, ModernBERT-base outperforms the previous base model, and ModernBERT-large is roughly on par with the best large models, while being significantly more efficient. In the BEIR benchmark, ModernBERT shows good performance for both single-vector and multiple-vector acquisitions.
In addition to strong downstream performance, ModernBERT is also the fastest and most memory-efficient encoder, designed for general GPU inference.
In summary, ModernBERT is an updated, streamlined, and more efficient version of BERT that provides faster and higher quality results across many information retrieval and natural language processing tasks.
The internal mechanism of the o1 and o3 models, and similar reasoning AI models, is to train the AI model with a chain of thought (CoT) reasoning process, which is represented by tokens. The meta-researcher behind it Training large language models for reasoning in continuous latent spaces Interesting observations:
However, we argue that linguistic space is not always optimal for inference. For example, most word tokens are primarily intended for textual consistency and are not required for inference. Some important tokens require complex planning and pose a major challenge for LLMs.. To explore the possibilities of LLM inference in an unrestricted latent space instead of using natural language, Introducing a new paradigm: the Coconut (Continuous Chain of Thought).
The authors observe that the last hidden state of the LLM may be more expressive than the output linguistic token. This is similar to thinking about geometry problems by visualizing them instead of talking about them verbally. Words sometimes limit thinking.
Unlike traditional Chain of Thought (CoT) methods, where inferences are expressed through word tokens, Coconut leverages the last hidden state of the LLM as a “continuous thought” that is directly fed back into the model as subsequent input embeddings. This moves away from mapping to word tokens and allows LLM to reason in a more flexible and open-ended space.
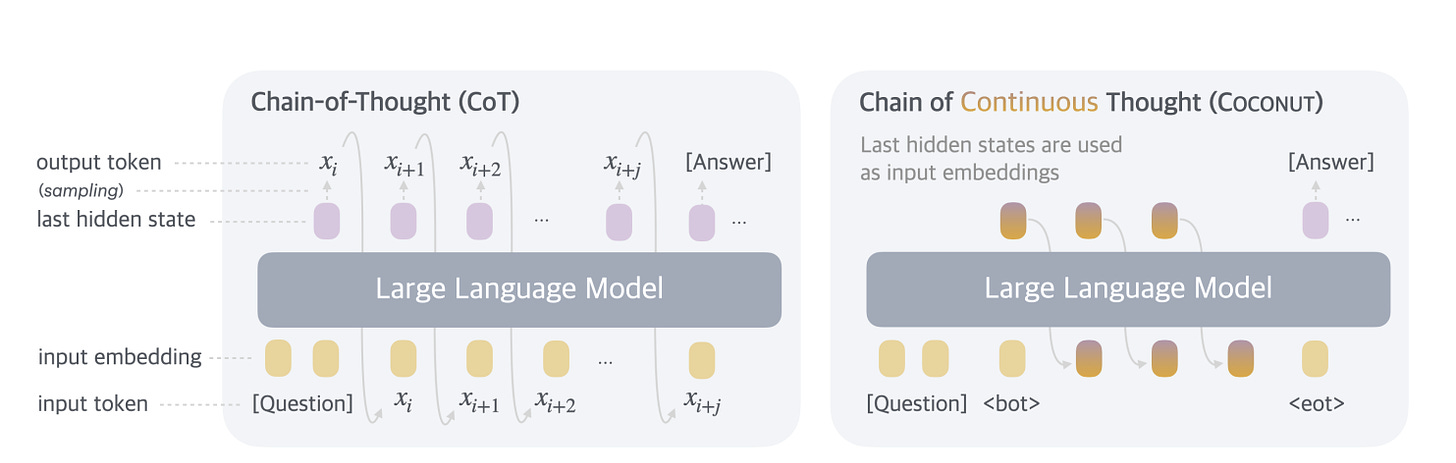
The main advantage of this potential reasoning paradigm is the emergence of sophisticated patterns of reasoning, especially the ability to encode multiple potential next reasoning steps within a continuous thought.
Continuous thinking allows encoding multiple alternative next inference steps, allowing the model to perform breadth-first search (BFS) rather than prematurely committing to a single deterministic path like CoT. problem. Coconut performs better than CoT on certain logical reasoning tasks that require significant backtracking during planning, with fewer thought tokens during reasoning.
Latent spaces allow us to defer some decisions that are “locked in” by choosing specific tokens, making them better suited for inference and allowing for better searches.
Experiments show that Coconut improves the performance of mathematical reasoning (GSM8k) and logical reasoning (ProntoQA, ProsQA), demonstrating a more efficient inference process while significantly reducing the tokens generated during inference. has been proven.
The authors employ a multi-step training strategy inspired by previous work that utilizes linguistic inference chains to guide the learning process. This method effectively switches between “verbal mode” and “latent mode,” using special tokens that mark the beginning and end of latent thinking.
This study shows the potential for extending latent inference to more complex problems. This first step could lead to important advances in inference models. AI reasoning models can reflect through internal thought (using latent spatial weights) as a different process than verbally expressing chains of thought (by outputting specific tokens). can.
