


3.5 years ago, Accelerate was a simple framework aimed at facilitating training of multi-GPU and TPU systems by making low-level abstractions that simplify raw Pytorch training loops.
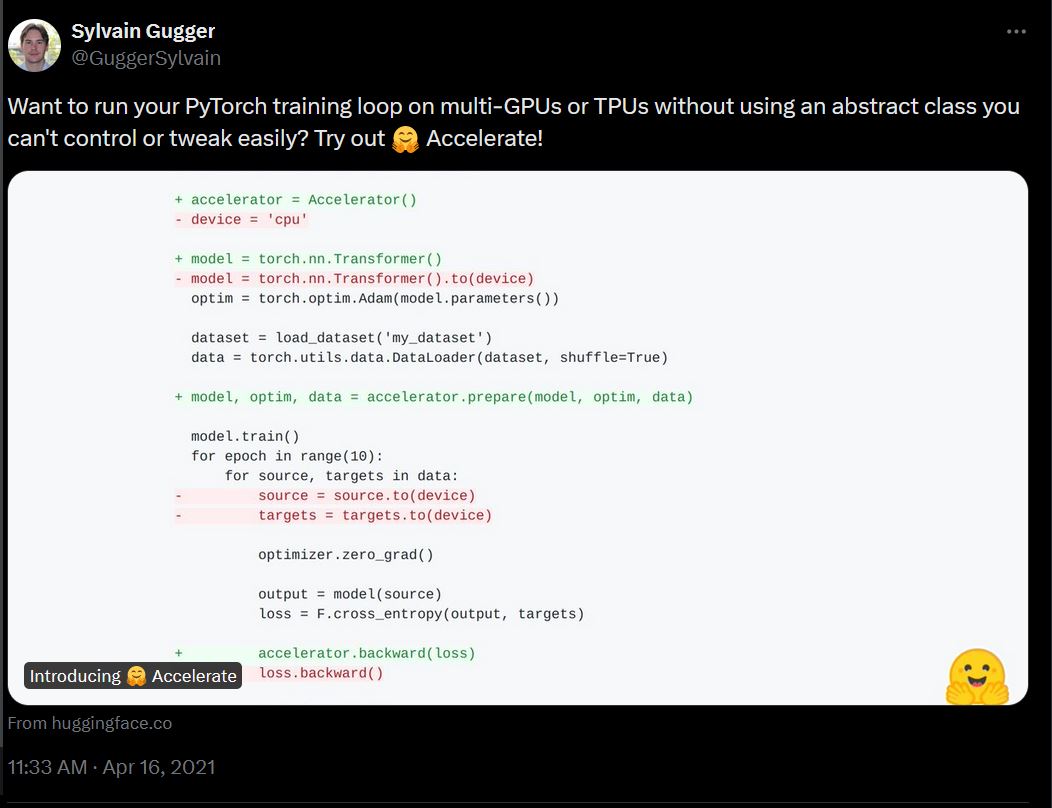
Since then, Accelerate has expanded into a multifaceted library aimed at tackling many common issues with age large training and large models, with 405 billion parameters (LAMA) being the new language model size. This includes:
Flexible low-level training API. It allows training of six different hardware accelerators (CPU, GPU, TPU, XPU, NPU, MLU), while maintaining an easy-to-use command line interface aimed at configuring and running scripts in a variety of hardware configurations, while still maintaining 99% of the original training loop. Although LLMS has multiple devices, it also allows you to train your LLMS with small calculations through techniques such as parameter-efficient fine tuning (PEFT).
These three facets made Accelerate the basis for almost every package of hugging faces, including transformers, diffusers, PEFTs, TRLs and more.
As the package has been stable for almost a year, we look forward to announce that as of today we are releasing the first release candidates for Accelerate 1.0.0.
This blog will explain in detail:
Why did we decide to do 1.0? What is the future to accelerate? Also, where do you think the whole Pytorch is heading? What are the broken changes and blame that have occurred? Also, how can you easily move?
Why 1.0?
Plans to release 1.0.0 have been in work for over a year. The API is centered around the accelerator side at the moment we wanted it to, simplifying much of the configuration and making it more expandable. However, I knew there were some missing pieces before calling Accelerate’s “base” functionality completely.
With the changes made in 1.0, Accelerate is ready to tackle new technology integrations while stabilizing its user-facing APIs.
The acceleration future
Now that 1.0 is almost complete, you can discover that the integration path accelerates, focusing on new techniques that come up throughout the community.
Deep speed is likely to work in general as part of multi-model deep speed support, but we found that major changes to the overall API may ultimately be required as we work to support simple wrapping to prepare models for multi-model training scenarios. With Torchao and Torchitan picking up steam, they all suggest a future for Pitorch. With the aim of supporting FP8 training, more native support for the new distributed sharding API, and newer version of FSDPV2, we predict that as the framework slowly stabilizes, internal and general usage APIs of the accelerator rate will need to be changed (preferably not too dramatic) to meet these needs. Riding on Torchao/FP8, many new frameworks have brought about different ideas and implementations on how to make FP8 training work and stabilize (e.g. Transformer_Engine, Torchao, MS-AMP, Nanotron, etc.). Our aim to accelerate is to house each of these implementations in a simple configuration in one place, allowing users to explore and test each one. This is especially a field of research that accelerates NVIDIA’s FP4 training support rapidly along the way (not intended as a pun) and we want to make sure that not only can support each of these methods, but each aims to provide a solid benchmark to show trends (with minimal adjustments) compared to native BF16 training.
We are extremely excited about the future of distributed training in the Pytorch ecosystem. We want to ensure that it provides and accelerates lower barriers to entry to these new techniques. In doing so, we hope that the community will continue to experiment and learn together to find the best way to train and scale larger models on more complex computing systems.
How to try it
To try out the first release candidates to access today, use one of the following methods:
PIP Installation – PRE Accelerate Docker Pull Huggingface/Accelerate: gpu-release-1.0.0rc1
Valid release tags are:
GPU-RELEASE-1.0.0RC1 CPU-RELEASE-1.0.0RC1 GPU-FP8-TRANSFORMERENGINE-RELEASE-1.0.0RC1 GPU-DEEPED-RELEASE-1.0.0RC1
Immigration support
Below are all the deprecated details that have been enacted as part of this release.
Passing dispatch_batches, split_batches, ven_batches, and use_seedable_sampler to the accelerator requires creating and handling accelerate.utils.dataloaderconfiguration(). accelerator(). use_fp16 and acceleratorState(). use_fp16 has been deleted. This is accelerator.mixed_precision == “fp16” accelerator(). Check autocast() to stop accepting cache_enabled argument. Instead, you should use an AutoCastkWargs() instance that handles this flag (among other things) accelerators (kwargs_handlers = (autocastkwargs(cache_enabled = true))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))) The acceleration.utils.modeling.shard_checkpoint should be replaced with split_torch_state_dict_into_shards. Instead, you must manually enable rich traceback by setting Accelerate_Enable_rich = 1. FSDP setting FSDP_BACKWARD_PREFETCH_POLICY has been replaced by FSDP_BACKWARD_PREFETCH
Close thoughts
Thank you for using Accelerate. It’s amazing to see small ideas transform into over 100 million downloads and nearly 300,000 downloads every day in recent years.
With this release candidate, we hope to provide the community with the opportunity to try and move to 1.0 before the official release.
Stay tuned to Github and Socials and stay tuned for more details!
