


Building applications with LLMS requires more than just quality to consider. Speed and price are equally important in many use cases.
For consumer applications and chat experiences, speed and responsiveness are important for user engagement. Users expect a response near instants, and delays can directly lead to reduced engagement. When building more complex applications that involve tool use or agent systems, speed and cost become even more important and limit the overall system’s capabilities. The time taken by sequential requests to LLMS can be quickly stacked for each user request that is added to the cost.
This is why ArtificialAnalys (@artificialanlys) has developed a leaderboard that evaluates price, speed and quality across over 100 serverless LLM API endpoints, and is now hugging your face.
Find the leaderboard here!
LLM Performance Leaderboard
The LLM Performance Leaderboard aims to provide comprehensive metrics to help AI engineers decide which LLM (both open and proprietary) and API providers to use in AI-enabled applications (both open and proprietary).
When making decisions about which AI technology to use, engineers need to consider quality, price, speed (latency, throughput). The LLM Performance Leaderboard brings all three together to allow decision-making in one place, both unique and open models.
Source: LLM Performance Leaderboard
Metric Coverage
The reported metrics are:
Quality: Simplified index for comparing model quality and accuracy. It is calculated based on metrics such as MMLU, MT Bench, Humanval score, and report rankings for model authors and chatbot arenas. Context window: The maximum number of tokens that LLM can operate at any time (including both input and output tokens). Pricing: The price charged by the provider to query the model for inference. Reports the input/output per token and “blend” pricing, and the “blend” pricing that compares the hosting provider to a single metric. The price of the input and output is blended at a 3:1 ratio (that is, assuming the input length is three times longer than the output). Throughput: The speed at which an endpoint outputs a token during inference, measured in tokens per second (often called token/s or “TPS”). Report median p5, p25, p75, and p95 values measured over the previous 14 days. Latency: How long does it take for an endpoint to respond after a request is sent? Known as the time of the first token (“TTFT”), it was measured in seconds. Report median p5, p25, p75, and p95 values measured over the previous 14 days.
See the complete methodology page for further definitions.
Test your workload
Leaderboards allow you to investigate performance across several different workloads (a total of six combinations).
Changes in prompt length: ~100 tokens, ~1K tokens, ~10k tokens. Run parallel queries: 1 query, 10 parallel queries.
Methodology
We tested all API endpoints on the leaderboard eight times a day, and the leaderboard numbers represent median measurements over the last 14 days. Also, there is a breakdown of percentiles within the collapsed tab.
Currently, quality metrics are collected for each model and display results reports by modelers, but look at this space as you start sharing independent quality rating results on each endpoint.
See the complete methodology page for further definitions.
Highlights (see May 2024, latest leaderboard)
The language model market exploded with complexity last year. The launches that have rocked the market within the last two months include Anthropic’s Claude 3 series, Databricks’ DBRX, Cohere’s Command R Plus, Google’s Gemma, Microsoft’s Mixtral 8x22B, Meta’s Llama 3’s Metral’s Mixtral 8x22b, and Metral’s Meta’s Llama 3’s Meta’s Llama 3’s Meta’s Llama 3. From Claude 3 Opus to Llama 3 8b, there is a 300x price range. This is more than two digits! API providers have increased model launch speed. Within 48 hours, seven providers had offered the Llama three models. Talk about the demand for new open source models and the competitive dynamics among API providers. Important models highlighting high quality segments: high quality, higher than normal price and slower: GPT-4 Turbo and Claude 3 OPUS Medium quality, Price and speed: Llama 3 70B, Mixtral 8x22B, Command R+, Gemini 1.5 Pro, DBRX low quality,
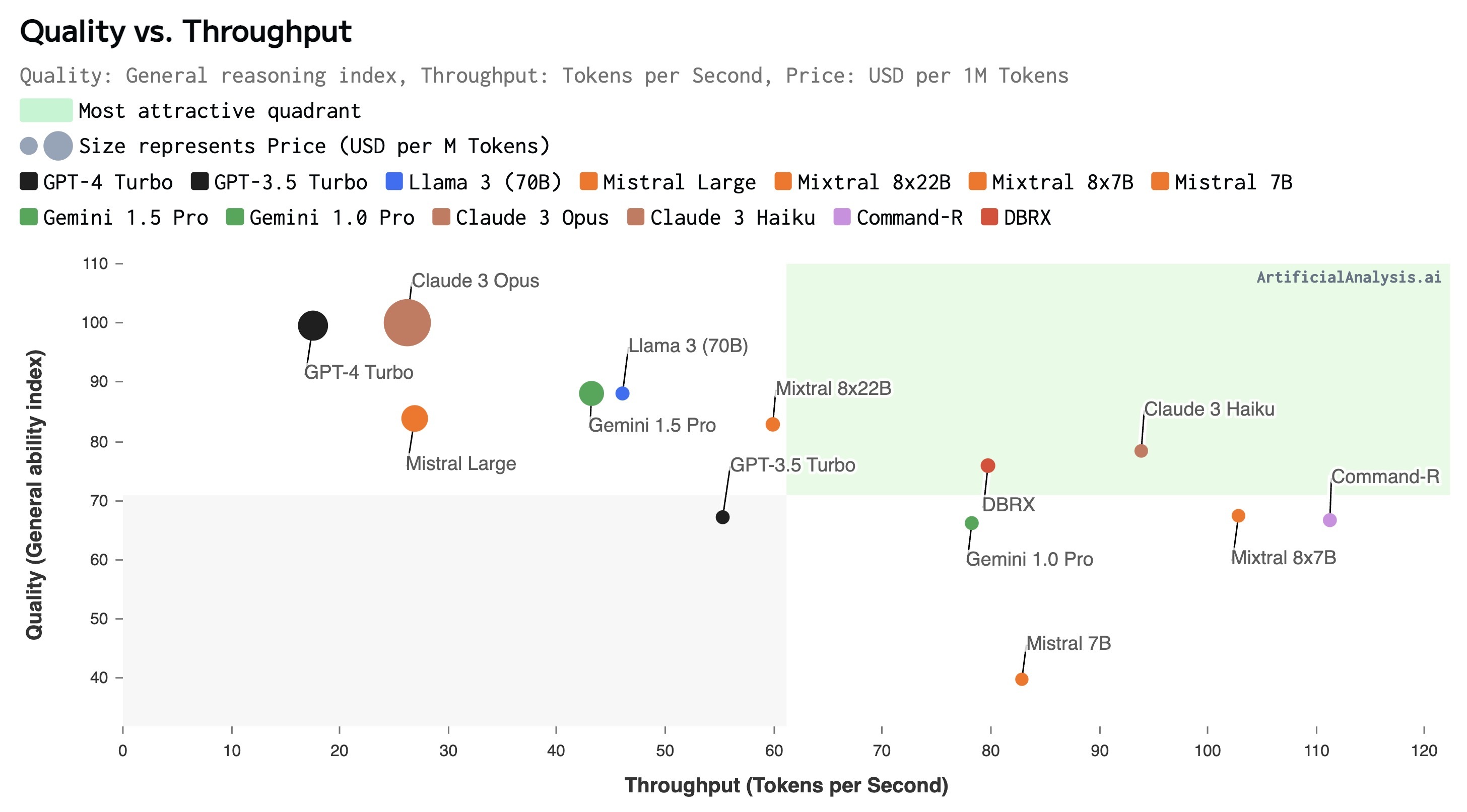
The Quality and Throughput (Token/s) chart shows a range of options with a variety of quality and performance characteristics.
Source: Artificial analysis/model
Example use case: Speed and price are just as important as quality
In some cases, design patterns with multiple requests with faster and cheaper models can not only be lower in cost compared to using a single larger model, but also improve overall system quality.
For example, consider a chatbot that requires you to browse the web to find relevant information from recent news articles. One approach is to perform searches using large, high-quality models such as the GPT-4 turbo, reading and processing one of the top articles. The other is to use a small, fast model like the Llama 3 8b to read and extract highlights in parallel from dozens of web pages, and then evaluate and summarise the most relevant results using the GPT-4 turbo. The second approach is more cost-effective and likely to give you quality results even after accounting for 10x content.
Please contact us
Follow us on Twitter and LinkedIn for updates. It is available either and via message on our website and email.