



TL;DR: We benchmarked two representative agent AI workload components, text embedding and text generation, on two Google Cloud Compute Engine Xeon-based CPU instances: N2 and C4. The results consistently show that C4 has 10x to 24x higher throughput than N2 for text embedding and 2.3x to 3.6x higher throughput than N2 for text generation. Considering the price, C4’s hourly rate is about 1.3 times that of N2. In this sense, C4 maintains a 7x to 19x TCO (total cost of ownership) advantage compared to N2 in text embedding and a 1.7x to 2.9x TCO advantage in text generation . This result shows that lightweight Agentic AI solutions can be deployed entirely on CPUs.
introduction
People believe that the next frontier in artificial intelligence is agent AI. The new paradigm uses the know-reason-action pipeline to combine the advanced reasoning and iterative planning capabilities of LLM with powerful contextual understanding enhancements. Context understanding capabilities are provided by tools such as vector databases and sensor inputs to build more context-aware AI systems that can autonomously solve complex multi-step problems. Additionally, LLM’s function-call capabilities allow AI agents to take direct actions, going far beyond chats provided by chatbots. Agentic AI offers exciting prospects for improving productivity and operations across industries.
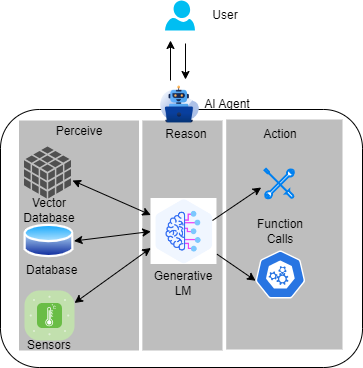
More and more people are introducing more and more tools into their agent AI systems, and most of these tools now run on the CPU. This raises concerns that this paradigm introduces non-negligible host accelerator traffic overhead. At the same time, model builders and vendors are building smaller yet more powerful small language models (SLMs), with the latest examples being Meta’s 1B and 3B llama3.2 models, advanced multilingual text generation and One example is the tool call function. Additionally, CPUs are evolving and starting to offer enhanced AI support, with the introduction of a new AI tensor accelerator, Intel Advanced Matrix Extensions (AMX), on 4th generation Xeon CPUs. Combining these three threads, it would be interesting to see the potential of a CPU that can host an entire agent AI system, especially when using SLM.
In this post, we benchmark two typical components of agent AI: text embedding and text generation, and compare the performance gains of each CPU generation for these two components. We selected Google Cloud Compute Engine C4 and N2 instances for comparison. The logic behind it is: C4 is powered by 5th generation Intel Xeon processors (codenamed Emerald Rapids), the latest generation of Xeon CPUs available on Google Cloud, and integrates Intel AMX for improved AI performance. N2 is powered by 3rd generation Intel Xeon processors (codenamed Ice Lake), the previous generation of Xeon CPUs on Google Cloud, and only has AVX-512 and no AMX. Demonstrates the benefits of AMX.
To measure performance, use Optimal Benchmark, Hugging Face’s unified benchmark library for multi-backends and multi-devices. Benchmarks are run on the optimum-intel backend. optimal-intel is a Hugging Face acceleration library for accelerating end-to-end pipelines on Intel architecture (CPU, GPU). The benchmark cases are as follows.
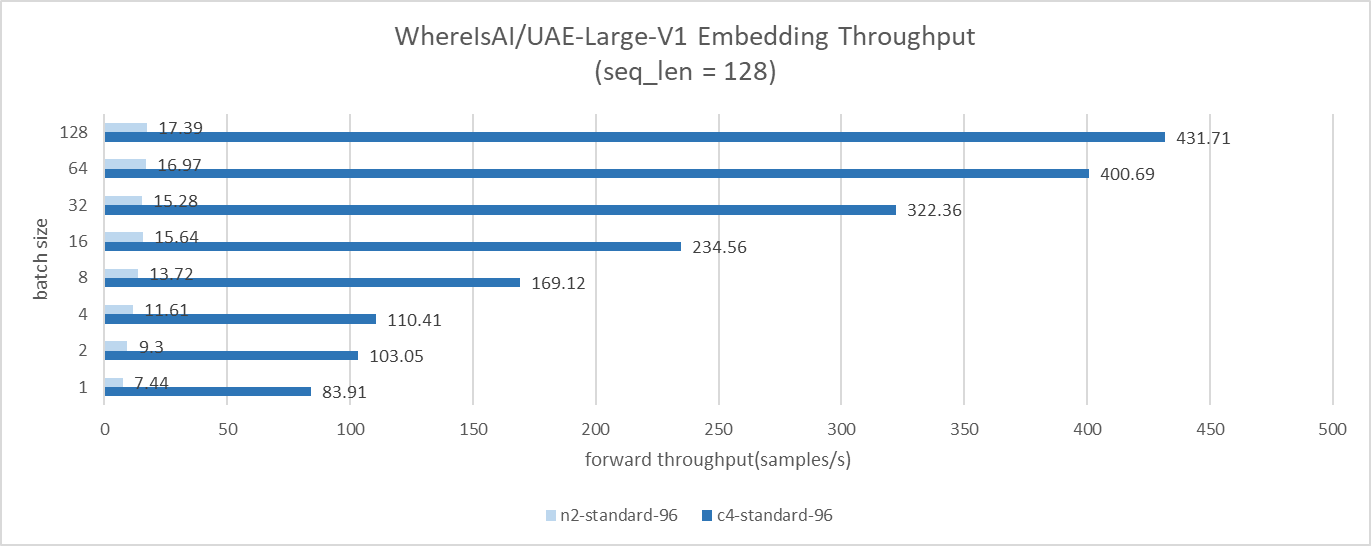
For text embedding, we use the WhereIsAI/UAE-Large-V1 model with an input sequence length of 128 and sweep the batch size from 1 to 128 for text generation. Use the metal-llama/Llama-3.2-3 model with input sequence length 256. Print a sequence length of 32 and sweep the batch size from 1 to 64.
Creating an instance
N2
Access the Google Cloud console and click (Create VM) under your project. Next, follow the steps below to create a single 96 VCPU instance that accommodates one Intel Ice Lake CPU socket.
Select N2 on the (Machine Configuration) tab and specify the machine type as n2-standard-96. Next, you need to set the CPU platform as shown in the image below.
Set the OS and storage tabs as below.
Leave the other settings as default and click the Create button.
You now have one N2 instance.
C4
Follow these steps to create a 96 vcpu instance that corresponds to one Intel Emerald Rapids socket. Note that this article uses the same CPU core count on C4 and N2 to ensure equal core count benchmarks.
Select C4 on the (Machine Configuration) tab and specify the machine type as c4-standard-96. You can also configure your CPU platform to turn on All-Core Turbo for more consistent performance.

Configure the OS and storage as N2. Leave the other configurations as default and click the Create button.
You now have one C4 instance.
Set up the environment
You can easily create an environment by following the steps below. For better reproducibility, list the version and commit you are using in the command.
SSH into your instance $ git clone https://github.com/huggingface/optimum-benchmark.git $ cd ./optimum-benchmark $ git checkout d58bb2582b872c25ab476fece19d4fa78e190673 $ cd ./docker/cpu $ sudo docker build . -t $ sudo docker run -it –rm –privileged -v /home/:/workspace /bin/bash
Now that you are inside the container, do the following steps:
$ pip install “optimum-intel(ipex)”@git+https://github.com/huggingface/optimum-intel.git@6a3b1ba5924b0b017b0b0f5de5b10adb77095b $ pip install torch==2.3.1 torchvision torchaudio –index-url https:/ /download.pytorch.org/whl/cpu $ python -m pip install intel-extension-for-pytorch==2.3.10 $ cd /workspace/optimum-benchmark $ pip install .(ipex) $ export OMP_NUM_THREADS= 48 $export KMP_AFFINITY=granularity=fine,compact,1,0 $exportKMP_BLOCKTIME= 1 $pip install hugface hub $ hugface-cli Log in and enter your Hug Face Token to access your llama model
benchmark
Embedding text
To benchmark WhereIsAI/UAE-Large-V1, you need to update examples/ipex_bert.yaml in the optimum-benchmark directory as follows. Both N2 and C4 have two NUMA domains per socket, so change the swamp binding to 0,1. You can double check with lscpu.
— a/examples/ipex_bert.yaml +++ b/examples/ipex_bert.yaml @@ -11,8 +11,8 @@ Name: ipex_bert Launcher: umactl: true umactl_kwargs: – cpunodebind: 0 – membind: 0 + cpunodebind: 0,1 + membind: 0,1 Scenario: Latency: true @@ -26,4 +26,4 @@ Backend: no_weights: false Export: true torch_dtype: bfloat16 – Model: bert-base-uncased + Model: WhereIsAI/UAE-Large-V1
Then run the benchmark: $optimal benchmark –config-dir example/ –config-name ipex_bert
Generating text
You can benchmark meta-llama/Llama-3.2-3 by updating examples/ipex_llama.yaml as below.
— a/examples/ipex_llama.yaml +++ b/examples/ipex_llama.yaml @@ -11,8 +11,8 @@ Name: ipex_llama Launcher: umactl: true umactl_kwargs: – cpunodebind: 0 – membind: 0 + cpunodebind: 0,1 + membind: 0,1 Scenario: Latency: true @@ -34,4 +34,4 @@ Backend: Export: true no_weights: false torch_dtype: bfloat16 – Model: TinyLlama/TinyLlama-1.1B-Chat-v1.0 + Model: metal-llama/Llama -3.2- 3B
Then run the benchmark: $optimal benchmark –config-dir example/ –config-name ipex_llama
Results and conclusions
Text embedding results
GCP C4 instances deliver approximately 10x to 24x higher throughput compared to N2 for text embedding benchmarks.
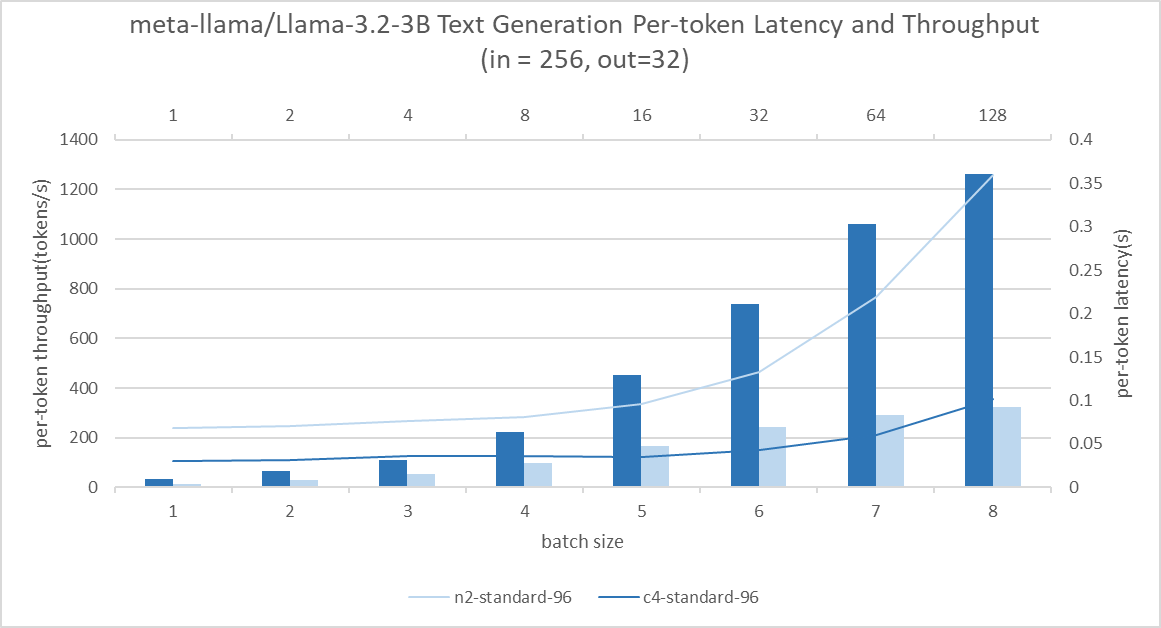
Text generation result
Consistently, C4 instances have approximately 2.3x to 3.6x higher throughput than N2 on text generation benchmarks. Across batch sizes from 1 to 16, we achieved a 13x increase in throughput without significantly compromising latency. Enables concurrent processing of queries without sacrificing user experience.
conclusion
In this post, we benchmarked two representative workloads for Agent AI on Google Cloud Compute Engine CPU instances: C4 and N2. The results showed that the improved AMX and memory capabilities of Intel Xeon CPUs resulted in significant performance improvements. Intel released its Xeon 6 processor with P cores (codenamed Granite Rapids) a month ago. This improves Llama 3’s performance by up to 2x. With the new Granite Rapids CPUs, we believe we can consider implementing lightweight Agentic. The AI solution resides entirely on the CPU, avoiding the overhead of intensive host accelerator traffic. Once the Granite Rapids instance is added to Google Cloud Compute Engine, we will benchmark it and report the results.
Thank you for reading!
