


SetFit is a promising solution to common modeling problems. How to deal with the lack of labeled data for training. Developed with Intel Labs and UKP Lab’s Hugging Face research partners, SetFit is an efficient framework for the fine-tuning of a small number of intercultural models.
setFit achieves high accuracy with little labeled data – for example, SetFit outperforms GPT-3.5 at the 3-shot prompt, and in 5-shot it outperforms 3-shot GPT-4 at the Bank 77 financial intent dataset.
Compared to the LLM-based method, SetFit has two unique advantages:
There is no prompts or words: small numbers of in-context learning using LLMS require handcrafted prompts that are brittle in outcomes, phrasing sensitive, and rely on user expertise. SetFit fully distributes the prompts by generating rich embeddings directly from a few examples of labeled text.
Conding Speed: SetFit does not rely on LLMS such as GPT-3.5 or LLAMA2 to achieve high accuracy. As a result, it is usually faster (or even more) orders of magnitude to train and execute inference.
For more information about SetFit, see the paper, blog, code and data.
SetFit is widely adopted by the AI developer community, with around 100k downloads per month, and ~1500 SetFit models in the hub, growing on an average of four models per day.
Faster!
In this blog post, I will show you how to use setFit to accelerate 7.8x by optimizing the setFit model with 7.8x with setFit. We show how to achieve large throughput gains by performing a simple post-training quantization step on the model. This allows for production-grade deployment of SetFit solutions using Intel Xeon CPUs.
Optimum Intel is an open source library that accelerates an end-to-end pipeline built with face libraries that embrace Intel hardware. Optimum Intel includes several techniques for accelerating models, such as low-bit quantization, weight pruning of models, distillation, and acceleration runtime.
The runtimes and optimizations included with Optimum Intel facilitate Intel® Advanced Vector Extensions 512 (Intel® AVX-512), Vector Neural Network Instructions (VNNI), and Intel® Advanced Matrix Extensions (Intel® AMX). Specifically, all cores incorporate BFLOAT16 (BF16) and INT8 GEMM accelerators to accelerate deep learning training and inference workloads. AMX accelerated inference has been introduced in Intel Extensions for Pytorch 2.0 and Pytorch (IPEX) in addition to other optimizations for various common operators.
Pre-trained model optimization is easy to perform with optimal Intel. Here are many simple examples. Our blog comes with a notebook for a step-by-step walkthrough.
Step 1: Quantify the setFit model using the best Intel
To optimize your SetFit model, apply quantization to the model body using Intel Neural Compressor (INC), a part of optimal Intel.
Quantization is a very popular deep learning model optimization technique for improving inference speed. Minimizes the number of bits required to represent weights and activation of neural networks. This is done by converting a set of high-precision numbers into a low-bit data representation, such as INT8. Furthermore, quantization allows for faster calculations with lower accuracy.
Specifically, post-training static quantization (PTQ) is applied. PTQ can reduce memory footprint and latency for inference, but it preserves model accuracy and can be maintained without training with only a small unmarked calibration set. Before you begin, make sure that all the required libraries are installed and that version introduces features, so the best Intel version is at least 1.14.0.
PIP Installation – Upgrade – Strategy Eaver Optimum (IPEX)
Prepare the calibration data set
A calibration dataset should be able to represent the distribution of invisible data. Generally, preparing 100 samples is sufficient for calibration. We use the rotten_tomatoes dataset, as it consists of film reviews, as it is similar to the target dataset SST2.
First, load 100 random samples from this dataset. Next, to prepare the dataset for quantification, each example must be tokenized. You don’t need the “Text” and “Label” columns, so try deleting them.
Calibration_set = load_dataset(“rotten_tomatoes”split =“train”). Shuffle (Seed =42).range(100)))
def It will be turned into a token(example):
return Tokenzor (Example)“Sentence”), Paddy=“max_length”,max_length =512truncate =truth) tokenizer = setfit_model.model_body.tokenizer calibration_set = calibration_set.map(Token, remove_columns = (“Sentence”, “label”)))
Perform quantization
Before performing quantization, we need to define the desired quantization process – in our case – we use static training post-training quantization and perform quantization on the calibration dataset using optimum.intel.
from optimum.intel Import Incquantizer
from neural_compressor.config Import post trainingquantconfig setfit_body = setfit_model.model_body(0).auto_model Quantizer = incquantizer.from_pretrained(setfit_body)optimum_model_path = “/tmp/bge-small-en-v1.5_setfit-sst2-english_opt”
Quantization_config = post trainingquantconfig(approach =“static”backend =“IPEX”domain =“NLP”)Quantizer.Quantize(Quantization_Config = Quantization_config, Calibration_dataset = Calibration_set, save_directory = optimum_model_path, batch_size =1,) tokenizer.save_pretrained(optimum_model_path)
that’s it! Now you have a local copy of the Quantized SetFit model. Let’s test it.
Step 2: Benchmark reasoning
In the notebook, we have set up performance benchmark classes for calculating model latency and throughput, and accuracy measurements. Let’s use it to benchmark the best Intel model in two other commonly used ways.
I use Pytorch and 🤗Trans Library with FP32. Use Intel Extension from the Pytorch (IPEX) runtime using BF16 and trace the model using Torchscript.
Load the test dataset, SST2, and run the benchmark using Pytorch and 🤗Trans Library.
from Dataset Import load_dataset
from setFit Import setFitModel test_dataset = load_dataset(“SetFit/SST2”) ()“verification”)model_path = “dkorat/bge-small-en-v1.5_setfit-sst2-english”
setFit_model = setFitModel.from_pretrained(model_path)pb = performancebenchmark(model = setfit_model, dataset = test_dataset, optim_type =“bge-small (transformers)”,) perf_metrics = pb.run_benchmark()
The second benchmark uses Intel extensions for Pytorch (IPEX) using BF16 Precision and Torchscript traces. To use IPEX, simply import the IPEX library and apply ipex.optimize() to the target model. In this case, it is a SetFit (Transformer) model body.
dtype = torch.bfloat16 body = ipex.optimize(setfit_model.model_body, dtype = dtype)
For Torchscript traces, the token generates a random sequence based on the maximum input length of the model sampled from the token’s vocabulary.
tokenizer = setfit_model.model_body.tokenizer d = generate_random_sequences(batch_size =1length = tokenizer.model_max_length, vocab_size = tokenizer.vocab_size) body = torch.jit.trace(body, (d,), check_trace =errorstrict =error)setfit_model.model_body = torch.jit.freeze(body)
Now let’s run the benchmark using the Quantized Optimum model. First, you need to define a wrapper around the SetFit model that plugs in the inference quantized model body (instead of the original model body). You can then use this wrapper to run the benchmark.
from optimum.intel Import ipexmodel
class OptimumSetFitModel:
def __init__(self, setfit_model, model_body): model_body.tokenizer = setfit_model.model_body.tokenizer self.model_body = model_body self.model_head = setfit_model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.model.from_pretrained(optimum_model_path model_body = optimum_model)pb = performancebenchmark(model = optimum_setfit_model, dataset = test_dataset, optim_type =f “bge-small (optimum-int8)”model_path = optimum_model_path, autocast_dtype = torch.bfloat16,) perf_metrics.update(pb.run_benchmark())
result
Accuracy and latency in batch size = 1
BGE-SMALL (transformer) BGE-SMALL (IPEX-BFLOAT16) BGE-SMALL (OPTIMUM-INT8) Model size 127.32 MB 63.74 MB 44.65 MB Accuracy: Test set 88.4% 88.4% 88.1% LATENCY (BS = 1) 15.69 +/ – 0.57 MS 5.67 +/-0.66 +
When inspecting performance with batch size 1, the optimized model reduces latency by 3.45 times. Note that this is achieved with virtually no degradation of accuracy! It is also worth mentioning that the model size has been reduced by 2.85 times.
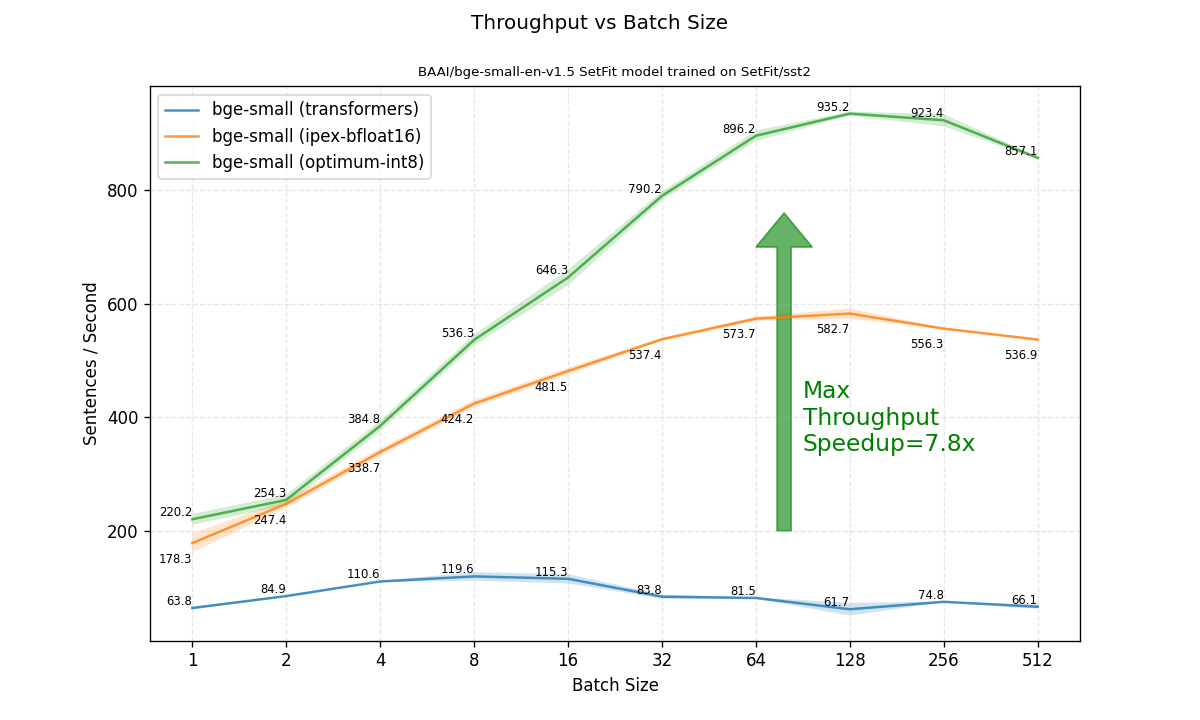
We move on to the main focus, which is reported throughput for various batch sizes. Here, optimization is gaining even greater speedups. Comparing the best achievable throughput (any batch size), the optimized model is 7.8 times faster than the original transformer FP32 model!
summary
In this blog post, I demonstrated how to use the quantization features that are best found in Intel to optimize your setFit model. After performing the rapid quantization procedure after training, we found that the accuracy level was preserved and inference throughput increased by 7.8 times. This optimization method is easily applicable to existing setFit deployments running on Intel Xeon.
reference
Lewis Tunstall, Nils Reimers, Unso Eun Seo Jo, Luke Bates, Daniel Korat, Moshe Wasserblat, Oren Pereg, 2022. “Efficient learning with no prompts.” https://arxiv.org/abs/2209.11055
