


In this blog post, I will introduce the concept of Matryoshka embedding and explain why they are useful. We will explain how these models are theoretically trained and how they can be trained using sentence transformers.
Additionally, we provide practical guidance on how to use Matryoshka embedded models and share a comparison between Matryoshka embedded models and regular embedded models. Finally, we recommend checking out an interactive demo that shows the power of these models.
table of contents
Understanding embedding
Embedment is one of the most versatile tools in natural language processing, enabling practitioners to solve a wide variety of tasks. Embedded essentially is a numerical representation of more complex objects, such as text, images, audio, etc.
Embedded models always generate embeddings of the same fixed size. You can then calculate the similarity of complex objects by calculating the similarity of each embedding!
This has a huge amount of use cases and acts as the backbone for recommended systems, search, one-shot or small number of learning, outlier detection, similarity search, paraface detection, clustering, classification, and more!
matryoshka embedding
As research progressed, new cutting-edge (text) embedding models began generating embeddings with increasingly high output dimensions. This means that all input text is represented using more values. This improves performance, but costs more efficient downstream tasks such as search and classification.
As a result, Kusupati et al. (2022) was inspired to create an embedded model that allows for reasonably reduced embedding without suffering too much from performance.
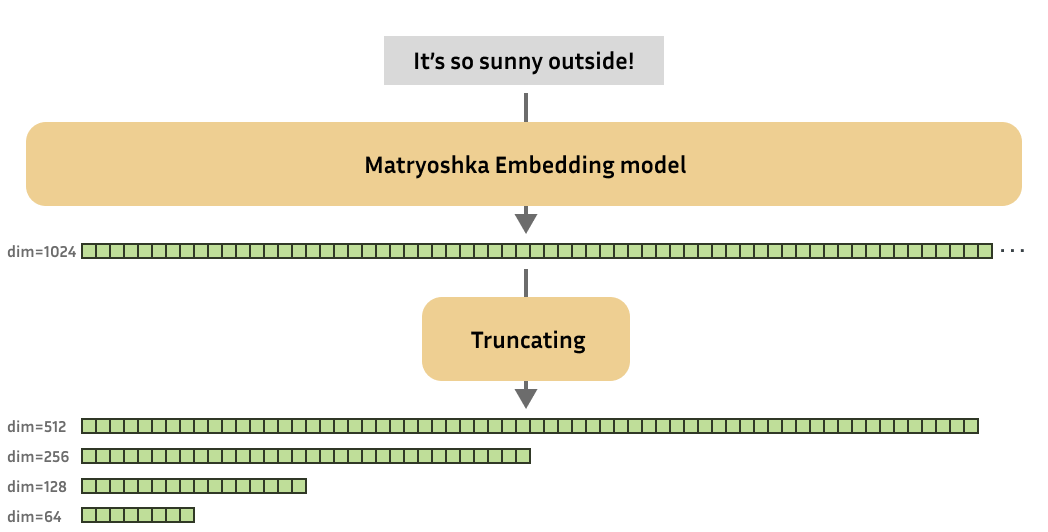
These Matrioschka embedding models are trained so that these small truncated embeddings still serve. In short, the Matryoshka embedding model can generate useful embeddings of various dimensions.
matryoshka doll
For those unfamiliar, the “Matrioshka dolls,” also known as “Russian Nest Dolls,” is a set of wooden dolls of reduced size arranged inside each other. Similarly, the Matryoshka embedded model aims to store more important information than previous dimensions. This feature of Matryoshka’s embedded model allows you to truncate the original (large) embeddings generated by the model, retaining enough information to work well in downstream tasks.
Why use the Matryoshka embedded model?
Such variable-sized embedding models are of great value for practitioners. for example,:
Suggested lists and re-ranking: Rather than performing downstream tasks (such as searching nearest neighbors) with a complete embedding, you can make embedding smaller and “final rankings” very efficiently. You can then use the full dimension to handle the remaining embeddings. Tradeoffs: Matryoshka models allow you to scale your embedded solution to the storage cost, processing speed and performance you want.
How is the Matryoshka embedded model trained?
In theory
The Matryoshka Representation Learning (MRL) approach can be adopted in almost any embedded model training framework. Training steps in an embedded model typically involve generating an embedding (such as text) for the training batch and using some loss function to create a loss value representing the quality of the generated embedding. The optimizer adjusts the weights of the model throughout training to reduce the loss values.
For the Matryoshka embedded model, the training step involves generating embeddings in the training batch, but we use some loss function to determine not only the quality of the full-size embedding, but also the quality of the embedding in various different dimensions. For example, output dimensions are 768, 512, 256, 128, and 64. The loss values for each dimension are added together to obtain the final loss values. The optimizer adjusts the weights of the model to reduce this loss value.
In fact, this incentivizes the model to frontload the most important information at the start of the embedding, so that it is preserved if the embedding is truncated.
In a sentence
Statement Transformers are a commonly used framework for training embedded models and have recently implemented support for the Matryoshka model. Training a Matrioshka embedded model using sentence transformers is very basic. Instead of applying some loss function to only full-size embeddings, the same loss function is applied to the truncated portion of the embedding.
For example, if the model’s original embedded dimensions are 768, you can now train at 768, 512, 256, 128, and 64. Each of these losses is optionally added with some weight.
from cente_transformers Import SentenceTransformer
from cente_transformers.losses Import Cosentloss, Matryoshkaloss Model = sensorecencetransformer (“Microsoft/MPNet-Base”) base_loss = cooperation(model = model) loss = matryoshkaloss(model = model, loss = base_loss, matryoshka_dims =(768, 512, 256, 128, 64), matryoshka_weight = (1, 1, 1, 1, 1) ) model.fit(train_objectives =((train_dataset, loss)), …,)
Training with Matryoshkaloss does not cause any significant overhead on training time.
References:
See the complete script below for an example of how to actually apply Matrio Shukaros:
Matryoshka_nli.py: In this example, we use MultiplenegativeSrankingloss using Matryoshkaloss to train a powerful embedded model using natural language inference (NLI) data. This is an adaptation of the NLI document. Matryoshka_nli_reduced_dim.py: In this example, we use Matryoshkaloss to train a powerful embedded model with a small maximum output dimension of 256. Matryoshka_sts.py: In this example, we use Cosentloss using Matryoshkaloss to train an embedded model with the training set of the STSBenchmark dataset. This is an adaptation of STS documents.
How do I use the Matryoshka embedded model?
In theory
In fact, getting an embedding from a Matryoshka embedded model works just like a regular embedded model. The only difference is that after receiving the embedding, you can optionally truncate them to a smaller dimension. Note that if the embedding is normalized, it may not exist anymore after it is truncated, so you may want to normalize it.
After truncating, it can be applied directly to the use case or saved for later use. After all, a small embedding in a vector database should give you a fair amount of speed!
Note that when you handle small embeddings for downstream tasks (search, clustering, etc.), getting small embeddings from the model is as fast as getting bigger ones.
In a sentence
Statements can load a Matrioshka embedded model just like any other model, but you can specify the desired embedding size using the truncate_dim argument. You can then perform inference using the SentencetransFormers.Encode function, and the embedding is automatically truncated to the specified size.
Let’s use a model trained using Matryoshka_nli.py in Microsoft/MPNet-Base.
from cente_transformers Import SentenceTransformer
from cente_transformers.util Import cos_sim matryoshka_dim = 64
model = centencetransformer(“Tomaarsen/mpnet-base-nli-matryoshka”truncate_dim = matryoshka_dim) embeddings = model.encode(((())
“The weather is very nice!”,
“It’s very sunny outside!”,
“He drove to the stadium.”,))
printing(Embeddings.shape) Similarity = cos_sim (Embedded)0),embedded(1:))
printing(Similarities)
Use different values for Matryoshka_dim to experiment freely and observe how it affects similarity. You can do this by running this code locally, running it in a cloud like Google Colab, or checking out the demo.
References:
Click here to see how to use the NOMIC V1.5 Matryoshka model
Note: NOMIC specifically requires f.layer_norm before embedding. As a result, the following snippet uses manual truncation for the desired dimension: All other models can use the constructor’s truncate_dim option, as shown in the previous example.
from cente_transformers Import SentenceTransformer
from cente_transformers.util Import cos_sim
Import torch.nn.functional As f model = sensorecencetransformer (“NOMIC-AI/NOMIC-IMBED-TEXT-V1.5”trust_remote_code =truth)Matryoshka_dim = 64
Embedded = model.encode((()
“Search_Query: What is TSNE?”,
“search_document: t-sistributed stochastic neighbor inbedding (t-sne) is a statistical method for visualizing high-dimensional data by giving each data point two or three-dimensional map locations.”,
“Search_Document: Amelia Mary Earhart was an American aviation pioneer and author.”,), convert_to_tensor =truth) embeddings = f.layer_norm(embeddings, modified_shape = (embeddings.shape (1))) Embedded (…, :matryoshka_dim) Similarity = cos_sim (Embedded (Embedded)0),embedded(1:))
result
Now that the Matryoshka model has been introduced, let’s take a look at the actual performance you can expect from Matryoshka’s embedded model and the regular embedded model. In this experiment, two models were trained.
Both of these models were trained on the Allnli dataset. This is a concatenation of SNLI and Multilinli datasets. Several different embedded dimensions were used to evaluate these models on the STSBenchmark test set. The results are plotted in the following diagram.
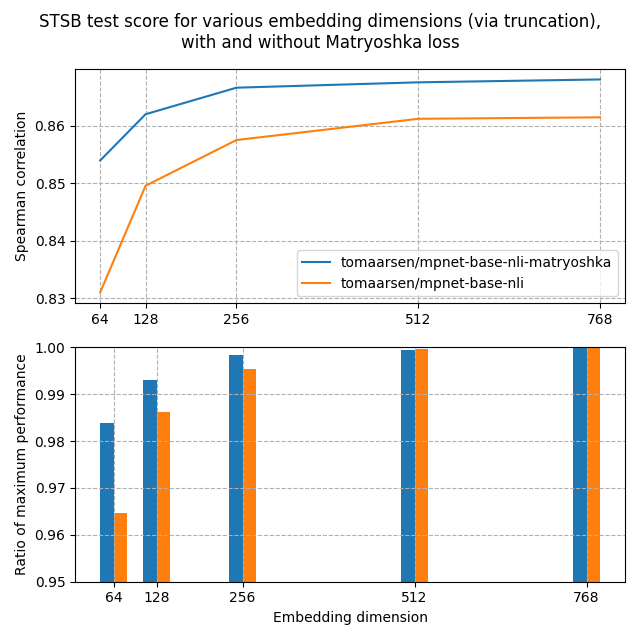
In the top image, we see that the Matryoshka model reaches a higher Spearman similarity than the standard model in all dimensions. This shows that the Matryoshka model is superior in this task.
Furthermore, the performance of the Matryoshka model drops much faster than the standard model. This is clearly shown in the second diagram showing performance in embedded dimensions for maximum performance. Even at 8.3% of the embedded size, the Matryoshka model maintains 98.37% of the performance, much higher than 96.46% on the standard model.
These findings indicate that embeddings by the Matriosuka model may be truncated. 1) You can save a lot of storage space without any noticeable hits in searches or 2) performance.
demo
This demo allows you to dynamically reduce the output dimensions of the NOMIC-AI/NOMIC-embed-Text-V1.5 Matryoshka Embedding model and observe how it affects search performance. All embeddings are calculated in the browser using the 🤗Transtrans.
reference
Kusupati, A., Bhatt, G., Rege, A., Wallingford, M., Sinha, A., Ramanujan, V., … & Farhadi, A. (2022). Matryoshka Expression Learning. Advances in Neural Information Processing Systems, 35, 30233-30249. https://arxiv.org/abs/2205.13147 Matryoshka Ebeddings – Documentation. (nd). https://sbert.net/examples/training/matryoshka/readme.html ukplab. (nd). github. https://github.com/ukplab/sentence-transformers unboxing nomic embed v1.5: renewable production embedding with matryoshka expression learning. (nd). https://blog.nomic.ai/posts/nomic-embed-matryoshka
