

: A Family of Code - Versa AI hub")
Code search has become essential in modern software development, allowing you to efficiently access relevant code snippets and documentation. Unlike traditional text search, which effectively handles natural language queries, code search must deal with unique challenges such as changing structure of programming languages, dependencies, and contextual relevance. As tools like GitHub Copilot grow in popularity, advanced code search systems become increasingly important to increase productivity and reduce errors.
Existing search models often struggle to capture programming-specific nuances such as syntax, control flow, and variable dependencies. These limitations hinder problem solving in code summarization, debugging, and translation between languages. Although text search models have made significant progress, they do not meet the specific requirements of code search, highlighting the need for specialized models that improve accuracy and efficiency across a variety of programming tasks. Models such as CodeBERT, CodeGPT, and UniXcoder have addressed aspects of code search using pre-trained architectures. Still, their small size and task-specificity limit their extensibility and versatility. Although Voyage-Code introduced extensive functionality, its closed-source nature has limited widespread adoption. This highlights the critical need for open source, scalable code search systems that generalize across multiple tasks.
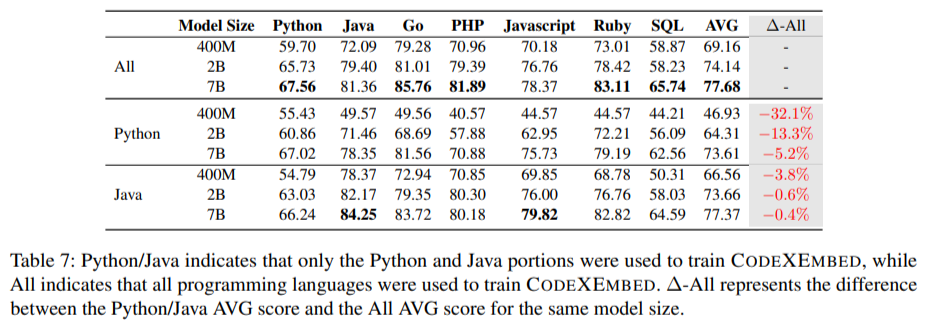
Researchers at Salesforce AI Research have introduced CodeXEmbed, an open source family of embedded models specifically designed for code and text search. These models are released in three sizes and 7 billion parameters: SFR-Embedding-Code-400M_R, SFR-Embedding-Code-2B_R, to accommodate a variety of programming languages and search tasks. CodeXEmbed’s innovative training pipeline unifies 12 programming languages and transforms 5 different code search categories into a unified framework. This model expands the scope that search systems can achieve by supporting a variety of tasks such as text-to-code search, code-to-text search, and hybrid search, providing unprecedented flexibility and performance. I will.
CodeXEmbed takes an innovative approach to converting code-related tasks into a unified query and answer framework, enabling versatility in a variety of scenarios. Text-to-code retrieval maps natural language queries to relevant code snippets, streamlining tasks such as code generation and debugging. Code-to-text search generates code descriptions and summaries to enhance documentation and knowledge sharing. Hybrid search integrates text and code data to effectively address complex queries that require technical and descriptive insights. Model training leverages contrastive loss to optimize the consistency of queries and answers while mitigating the influence of irrelevant data. Advanced techniques such as low-rank adaptation and token pooling increase efficiency without sacrificing performance.
Tests have been evaluated across a variety of benchmarks. On the CoIR benchmark, a comprehensive code search evaluation dataset covering 10 subsets and over 2 million entries, the 7 billion parameter model outperformed the previous state-of-the-art Voyage-Code model by more than 20%. Achieved improvement. . Notably, the 400-billion-parameter model and the 2-billion-parameter model also outperform Voyage-Code, demonstrating the scalability of the architecture across different sizes. CodeXEmbed also excels in text search tasks, with a 7 billion parameter model achieving an average score of 60 on the BEIR benchmark. The BEIR benchmark is a collection of 15 datasets covering a variety of search tasks, including question answering and fact checking.
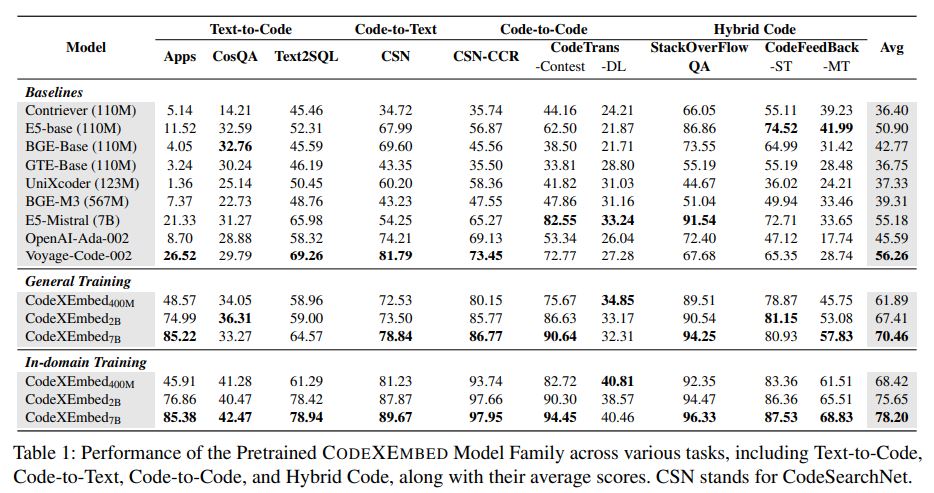
This model can capture code and power end-to-end acquisition augmentation generation (RAG) systems. For example, when applied to repository-level tasks such as code completion and problem solving, the 7 billion parameter model achieved remarkable results in benchmarks such as RepoEval and SWE-Bench-Lite. RepoEval, which focuses on repository-level code completion, improved top-1 accuracy when the model retrieved context-relevant snippets. CodeXEmbed outperformed traditional search systems on SWE-Bench-Lite, a curated dataset for solving GitHub problems.
Key takeaways from the study highlight the contribution and impact of CodeXEmbed in the advancement of code search.
The 7 billion parameter model achieved state-of-the-art performance with over 20% improvement on the CoIR benchmark and competitive results on BEIR. Demonstrated versatility across code and text tasks. The 400 million and 2 billion parameter models provide practical alternatives for environments with limited computational resources. This model addresses a wide range of code-related applications by integrating 12 programming languages and 5 search categories. Unlike closed systems such as Voyage-Code, CodeXEmbed fosters community-driven research and innovation. Integration with search extension generation systems improves outcomes for tasks such as code completion and problem solving. The use of contrastive loss and token pooling optimizes the retrieval accuracy and model adaptability.
In conclusion, code search has advanced with the introduction of the CodeXEmbed family by Salesforce. These models demonstrate unparalleled versatility and scalability by achieving state-of-the-art performance on CoIR benchmarks and excelling on text retrieval tasks. A multilingual and multitasking integrated framework that supports 12 programming languages positions CodeXEmbed as a vital tool for developers and researchers. Open source accessibility bridges the gap between natural language and code search while fostering community-driven innovation.
Check out the paper, 400M model, and 2B model. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram channel and LinkedIn group. Don’t forget to join the 65,000+ ML SubReddit.
🚨 Recommended open source platform: Parlant is a framework that transforms the way AI agents make decisions in customer-facing scenarios. (promotion)
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. His latest endeavor is the launch of Marktechpost, an artificial intelligence media platform. It stands out for its thorough coverage of machine learning and deep learning news that is technically sound and easily understood by a wide audience. The platform boasts over 2 million views per month, which shows its popularity among viewers.
📄 Introducing Height: The Only Autonomous Project Management Tool (Sponsored)
