


The Gemma model update was released two months after this post. See the latest version of this collection.
Gemma, the new family of cutting-edge open LLMS, was released by Google today! It’s great to see Google strengthen its commitment to open source AI and we’re excited to fully support the launch with a comprehensive integration into a hugging face.
Gemma comes in two sizes: efficient deployment of GPU and TPU and 2B versions for CPU and on-device applications and 7B parameters for development. Both are in the base and instruction tuned variants.
We’re working with Google to ensure optimal integration into the hugging face ecosystem. You can find four open access models (two base models and two fine-tuned models) in the hub. Some of the features and integrations released include:
table of contents
What is Gemma?
Gemma is a family of four new LLM models by Google based on Gemini. It comes in two sizes, 2B and 7B parameters, each with a base (previous) and instruction tuning version. All variants can run on different types of consumer hardware without quantization, and have a context length of 8K tokens.
A month after the original release, Google released a new version of The Instruct Models. This version has better coding capabilities, factuality, next instruction, and multi-turn quality. Also, this model doesn’t tend to start with “certainly”.
So, how good is the Gemma model? Here’s an overview of the base model and its performance compared to other open models on the LLM leaderboard (with better score increase):
The Gemma 7B is a very powerful model, with performance comparable to the best models with 7B weight, including the Mistral 7b. The Gemma 2B is an interesting model of its size, but it doesn’t score on the leaderboard as much as the best capable models in similar sizes, such as the PHI 2. We look forward to receiving feedback from our community about real-world usage.
Remember that the LLM leaderboard is particularly useful for measuring the quality of the chat model and is not from the chat model. We recommend running other benchmarks, such as chat benches, EQ benches, and LMSYS arena.
Prompt format
The base model does not have a prompt format. Like other base models, they can be used to continue the input sequence with a plausible continuation, or for zero shot/minimum shot inference. They are also a great foundation for tweaking in your own use case. The directed version has a very simple conversational structure.
<start_of_turn>User knock knock<end_of_turn>
<start_of_turn>The model there<end_of_turn>
<start_of_turn>User Lambda<end_of_turn>
<start_of_turn>Model Lambder?<end_of_turn>
This format must be replicated accurately for effective use. Later, we’ll show you how easy it is to recreate the instruction prompt using the chat templates available in Transformers.
Exploring the unknown
The technical reports contain information about the training and evaluation process for the base model, but do not provide detailed details about dataset configuration and preprocessing. We know that they are mainly trained with web documents, code, mathematical texts, and data from a variety of sources. Data was filtered to remove CSAM content and PII, and license checks.
Similarly, the GEMMA instructional model does not share details about fine-tuning datasets or hyperparameters related to SFT and RLHF.
demo
You can chat with Gemma Instruct Model on Hugging Chat! See this link: https://huggingface.co/chat/models/google/gemma-1.1-7b-it
🤗 I use a transformer
Transformers release 4.38 allows you to use Gemma to take advantage of all the tools within the Face Ecosystem to hug, such as:
Training and Inference Scripts and Examples Safe File Format (Safetenser) Bit and Byte (4-bit quantization), PEFT (Personal Efficient Fine Tuning), Flash Note 2 Utility and Helper Integrate with Tools to Export and Deploy Model Mechanisms
Additionally, the Gemma model is compatible with Cuda graphs and Torch.comPile(), providing about four times faster speeds when inference.
To use Gemma models using Transformer, install a recent version of the transformer.
PIP Installation – Upgrade Transformer
The following snippet shows how to use GEMMA-7B-IT in a transformer. It requires approximately 18 GB of RAM, including consumer GPUs such as the 3090 and 4090.
from transformer Import Pipeline
Import Torch pipe = pipeline (
“Text Generation”model =“Google/gemma-7b-it”model_kwargs = {“torch_dtype”: torch.bfloat16}, device =“cuda”) Message = ({“role”: “user”, “content”: “Who are you? Please answer in pirate language.”},) outputs = pipe(messages, max_new_tokens =256do_sample =truthtemperature =0.7top_k =50top_p =0.95
)Assistant_response = outputs(0) ()“generated_text”)(-1) ()“content”))
printing(Assistant_response)
Avast me, I was heartfelt. I’m a pirate on the high seas and am ready to plunder and plunder. Get ready for adventure and booty stories!
I used BFLOAT16. This is the reference accuracy and how all evaluations were performed. Running on float16 can be faster on hardware.
You can also automatically quantize the model and load it in 8-bit or 4-bit mode. A 4-bit load requires around 9 GB of memory and is compatible with many consumer cards and all GPUs on Google Colab. This is how to load a power generation pipeline in 4 bits.
Pipeline = Pipeline(
“Text Generation”,model=model,model_kwargs={
“torch_dtype”:torch.float16,
“Quantization_config”:{“load_in_4bit”: truth}},)
Check the model card for more information on using a transformer using a model.
JAX Weight
All Gemma model variants can be used in Pytorch as mentioned above. To load flax weight, you must use the flax revision from the repository as shown below.
Import Jax.numpy As JNP
from transformer Import AutoTokenizer, Flaxgemmaforcausallm model_id = “Google/Gemma-2B”
tokenizer = autotokenizer.from_pretrained(model_id) tokenizer.padding_side = “left”
Model, params = flaxgemmaforcausallm.from_pretrained(model_id, dtype = jnp.bfloat16, revision =“flax”,_do_init =error,) inputs = talknaser (“That’s true for Valencia and Malaga.”return_tensors =“NP”padding =truth)output = model.generate(** inputs, params = params, max_new_tokens =20do_sample =error)output_text = tokenizer.batch_decode(output.sequences, skip_special_tokens =truth))
(“Valencia and Malaga are two of Spain’s most popular tourist destinations. Both cities boast rich history and vibrant culture.”)
Check out this notebook for a comprehensive practical walkthrough on how to parallelize Jax inference in Colab TPU!
Integration with Google Cloud
You can deploy and train Gemma to Google Cloud via Vertex AI or Google Kubernetes Engine (GKE) using text generation inference and transformers.
To expand the gemma model from the hugging face, go to the model page and click (Expand)-> (Google Cloud). This will arrive at the Google Cloud console. Here you can click Deploy Gemma with vertex AI or GKE. Text Generation Inference powers Gemma with Google Cloud and is the first integration as part of its partnership with Google Cloud.
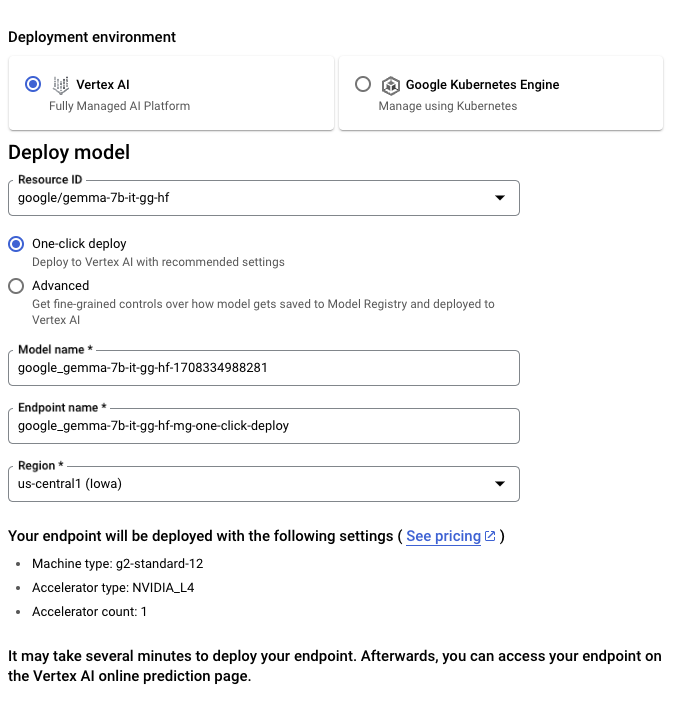
You can also access Gemma directly through the Vertex AI Model Garden.
To adjust your gemma model from facial hugs, go to the model page and click Train->Google Cloud. This allows you to access the Google Cloud Console and access the notebook and adjust your Gemma with vertex AI or GKE.
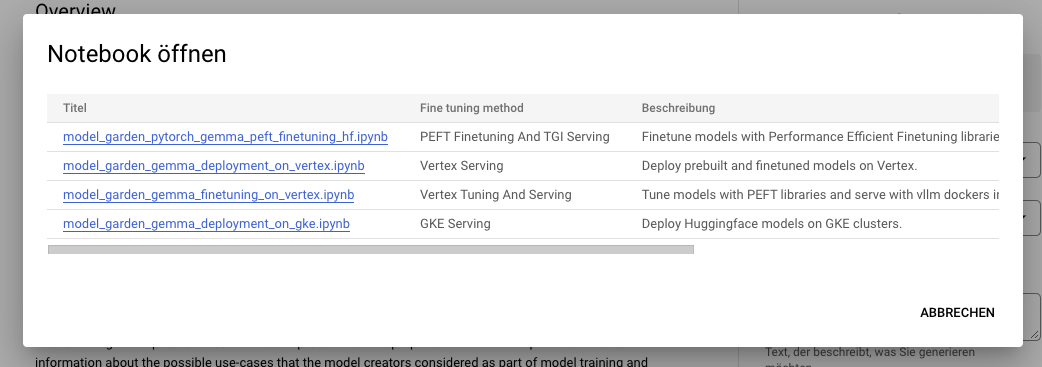
These integrations mark the first product we launch together as a result of our joint partnership with Google. Look forward to it more!
Integrating with inference endpoints
Gemma can hug the endpoint of Face’s inference, which uses text-generated inference as the backend. Text Generation Inference is a production-ready inference container developed by embracing the face to allow for easy deployment of large-scale language models. Features include continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-enabled logging and tracing.
To expand the GEMMA model, go to the model page and click (Expand)->(Inference Endpoints widget). In a previous blog post, you can learn more about the development of LLM, which hugs the endpoint of facial inference. Inference endpoints support message APIs via text-generated inference. This allows you to switch from another closed model to an open model simply by changing the URL.
OpenAI Import Openai client = openai(base_url =“” + “/v1/”,api_key =“”)chat_completion = client.chat.completions.create(model =“TGI”message = ({“role”: “user”, “content”: “Why is open source software important?”},), stream=true, max_tokens=500)
for message in chat_completion:
printing(message.choices(0).delta.content, end =“”))
Trl fine adjustment
LLMS training can be technically and computationally challenging. In this section, we will explore the tools available in the embracing face ecosystem to efficiently train Gemma on consumer GPUs.
Below is an example for tweaking Gemma with OpenAssistant chat datasets. It uses 4-bit quantization and Qlora to save memory and target the linear layer of all attention blocks.
First, install the nightly version of 🤗 TRL and clone the repository to access the training script.
PIP Install – U Trans TRL PEFT BitSandBytes Git Clone https:CD TRL
You can then run the script.
Accelerate raunch -Config_File Example/Accelerate_Configs/multi_gpu.Yaml -num_processes =1 \ Examples/scripts/sft.py \ – model_name google/gemma-7b \ – dataset_name OpenAssistant/oasst_top1_2023-08–twenty five \ -per_device_train_batch_size 2 \ -gradient_accumulation_steps 1 \ – learning_rate 2E-4 \ – save_steps 20_000 \ -use_peft \ -lora_r 16 -lora_alpha 32 \ -lora_target_modules q_proj k_proj v_proj o_proj \ –load_in_4bit \ –output_dir gemma-finetuned-openassistant
This takes about 9 hours to train on a single A10G, but can be easily lined up by adjusting the number of available GPUs.
Additional resources
Acknowledgments
Releasing such models with ecosystem support and evaluation is not possible without the contribution of many community members, such as Clémentine for LLM evaluation and Eleuther evaluation harness. Olivier and David for inference support for text generation. Simon is to develop new access control features for embracing faces. Arthur, Younes, and Sanchit to integrate Gemma into Transformers. Morgan for integrating Gemma into Optimum-nvidia (Coming); Nathan, Victor and Mishig have made Gemma available on Hugging Chat.
And thank you to the Google team for releasing Gemma and making it available to the open source AI community!
