


Today, we are publishing an early version of Gemini 2.5 Flash in preview via the Gemini API via Google AI Studio and Vertex AI. This new version builds on the popular 2.0 Flash foundation with significant upgrades to inference capabilities while still prioritizing speed and cost. Gemini 2.5 Flash is our first fully hybrid inference model that gives developers the ability to turn thinking on and off. This model also allows developers to set a thinking budget to find the right trade-offs between quality, cost, and delay. Without thinking, developers can maintain the high speed of 2.0 Flash and improve performance.
Our Gemini 2.5 model is a thinking model, allowing you to reason through your thoughts before responding. Instead of producing output immediately, models can perform “thinking” processes to better understand prompts, break down complex tasks, and plan responses. For complex tasks that require multiple reasoning steps (such as solving a math problem or analyzing a research question), the thought process allows the model to arrive at a more accurate and comprehensive answer. In fact, Gemini 2.5 Flash performs second only to 2.5 Pro at hard prompts in LMArena.
2.5 Flash has metrics comparable to other leading models at a fraction of the cost and size.
The most cost-effective thinking model
2.5 Flash continues to lead as the model with the best price/performance ratio.
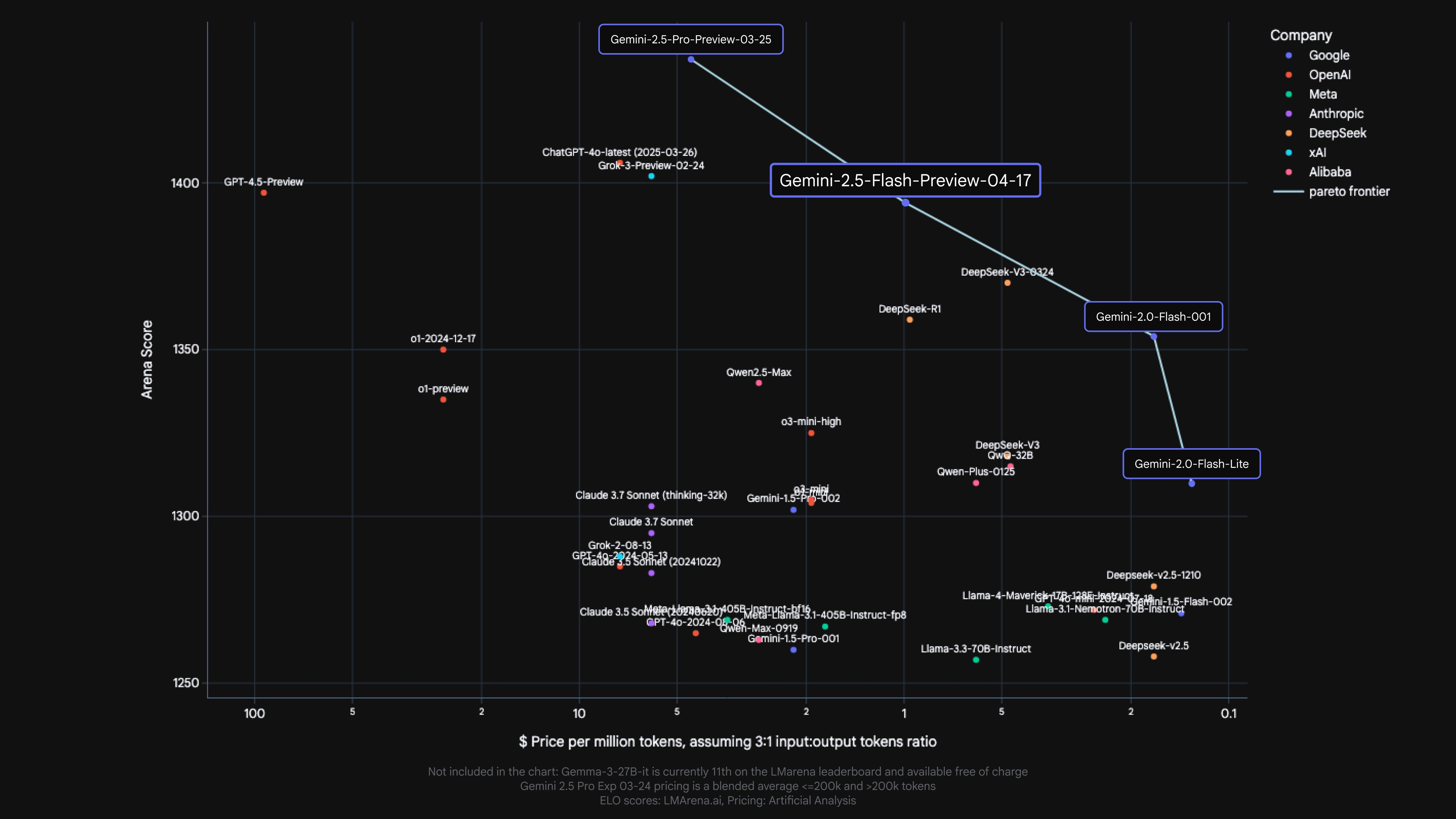
Gemini 2.5 Flash adds a new model to Google’s Pareto cost and quality frontier. *
Granular controls to manage your thoughts
We know that different use cases require different quality, cost, and latency tradeoffs. To give developers flexibility, we have enabled the setting of a thought budget that provides fine-grained control over the maximum number of tokens that a model can generate during a thought. As the budget increases, the model can make further inferences to improve quality. Importantly, though, the budget sets an upper bound on how much 2.5 Flash can think about, but the model won’t use the entire budget unless prompted.
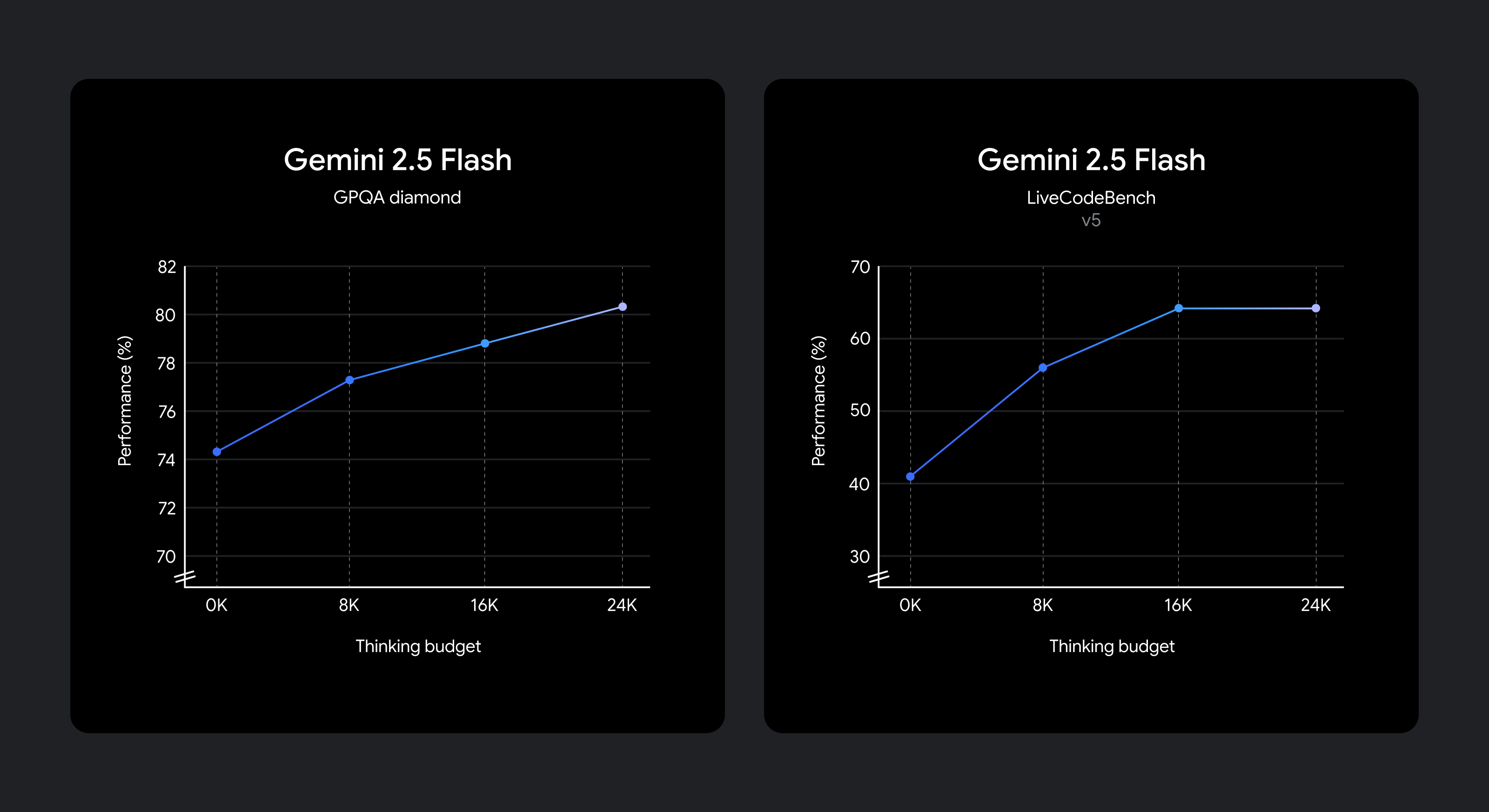
The quality of reasoning improves as the thinking budget increases.
The model is trained to know how long to think for a given prompt, so it automatically decides how long to think based on the perceived complexity of the task.
2.0 If you want better performance than Flash while minimizing cost and latency, set the thought budget to 0. You can also choose to set a specific token budget for the think phase using parameters or sliders in the Google AI Studio and Vertex AI APIs. For 2.5 Flash, the budget range is 0 to 24576 tokens.
The following prompt shows how much inference is used in 2.5 Flash’s default mode.
Prompts that don’t require much reasoning:
Example 1: “Thank you” in Spanish
Example 2: How many provinces are there in Canada?
Prompts requiring moderate reasoning:
Example 1: Roll two dice. What is the probability that they add up to 7?
Example 2: My gym has basketball pickup hours on MWF from 9:00 PM to 3:00 PM and on Tuesdays and Saturdays from 2:00 PM to 8:00 PM. If you work 5 days a week from 9pm to 6pm and want to play basketball for 5 hours during the week, create a schedule that will make everything work.
Prompts that require advanced reasoning:
Example 1: A cantilever beam of length L=3m has a rectangular cross section (width b=0.1m, height h=0.2m) and is made of steel (E=200 GPa). A uniformly distributed load w=5 kN/m is applied along the entire length and a point load P=10 kN is applied at the free end. Calculate the maximum bending stress (σ_max).
Example 2: Create a function Evaluate_cells(cells: Dict(str, str)) -> Dict(str, float) that calculates the values of cells in a spreadsheet.
Each cell contains:
Or a formula like “=A1 + B1 * 2” using cells like +, -, *, /, etc.
Requirements:
Resolve dependencies between cells. Handles operator precedence (*/ before +-). Detects a cycle and raises ValueError(“Cycle detected at “). There is no eval(). Use only built-in libraries.
Start building with Gemini 2.5 Flash today
Gemini 2.5 Flash with thinking capabilities is now available in preview via the Gemini API in Google AI Studio and Vertex AI, and in a dedicated dropdown in the Gemini app. We encourage you to experiment with the thinking_budget parameter and explore how controllable reasoning can help you solve more complex problems.
from google import genai client = genai.Client(api_key=”GEMINI_API_KEY”) response = client.models.generate_content( model=”gemini-2.5-flash-preview-04-17″, content=”You roll two dice. What is the probability that they add up to 7?”, config=genai.types.GenerateContentConfig( Thinking_config=genai.types.ThinkingConfig( Thinking_budget=1024 ) ) print(response.text)
python
Find a detailed API reference and thought guide in our developer documentation, or get started with code examples in the Gemini Cookbook.
We will continue to improve Gemini 2.5 Flash, with more features coming soon before we begin general availability in a full production environment.
*Model prices are taken from Artificial Analysis and company documentation.
