


Following the exciting announcement of Gemma 3 and Gemma 3 QAT, a family of cutting-edge open models that can run on a single cloud or desktop accelerator, we are furthering our vision for accessible AI. Gemma 3 gave developers powerful capabilities, and we’re now extending that vision to rich, real-time AI that runs directly on the devices you use every day, like your phone, tablet, or laptop.
We designed a new cutting-edge architecture to power next-generation on-device AI and support diverse applications, including evolving Gemini Nano’s capabilities. Created in close collaboration with mobile hardware leaders such as Qualcomm Technologies, MediaTek, and Samsung’s System LSI business, this next-generation foundation is optimized for ultra-fast multimodal AI to deliver truly personal and private experiences directly on your device.
Gemma 3n is the first open model built on this breakthrough shared architecture, and developers can start experimenting with the technology today with an early preview. The same advanced architecture powers the next generation of Gemini Nano, bringing these capabilities to a broader range of Google apps and on-device ecosystems, expected to be available later this year. With Gemma 3n, you can start building on this foundation that powers major platforms like Android and Chrome.
This graph ranks AI models based on their Chatbot Arena Elo scores. A higher score (higher number) indicates higher user preference. Gemma 3n ranks high among both popular proprietary and open models.
Gemma 3n leverages a Google DeepMind innovation called Per-Layer Embeddings (PLE) that significantly reduces RAM usage. Although the raw parameter counts are 5B and 8B, this innovation allows you to run larger models on mobile devices or live stream from the cloud with memory overhead comparable to 2B and 4B models. This means that the models can operate with dynamic memory footprints of just 2GB and 3GB. Please see the documentation for more information.
By exploring Gemma 3n, developers can get an early preview of the core capabilities of the open model and innovations in the mobile-first architecture available on Android and Chrome with Gemini Nano.
In this post, we’ll explain what’s new in Gemma 3n, our approach to responsible development, and how you can access the preview now.
Main features of Gemma 3n
Gemma 3n is designed for fast, low-footprint AI experiences that run locally and provides:
Optimized on-device performance and efficiency: Gemma 3n delivers significantly improved quality (compared to Gemma 3 4B), lower memory usage with innovations such as per-layer embedding, KVC sharing, and advanced activation quantization, and starts responding approximately 1.5x faster on mobile. Many-in-one flexibility: A model with 4B active memory usage that natively includes a nested state-of-the-art 2B active memory footprint submodel (thanks to MatFormer training). This provides the flexibility to dynamically trade off performance and quality on the fly without hosting separate models. Additionally, we introduce mix-and-match functionality in Gemma 3n to dynamically create submodels from the 4B model that can best fit the specific use case and associated quality/latency tradeoffs. Stay tuned for more information on this research in a future technical report. Privacy-first and offline-friendly: Local execution enables features that respect user privacy and function reliably even without an internet connection. Enhanced multimodal understanding with audio: Gemma 3n can understand and process audio, text, and images, greatly enhancing video understanding. Its audio capabilities allow this model to perform high-quality automatic speech recognition (transcription) and translation (speech to translated text). Additionally, the model accepts inputs interleaved across modalities, allowing for the understanding of complex multimodal interactions. (Coming soon) Improved multilingual functionality: Improved multilingual performance, especially for Japanese, German, Korean, Spanish, and French. Strong performance reflected in multilingual benchmarks such as 50.1% on WMT24++ (ChrF).
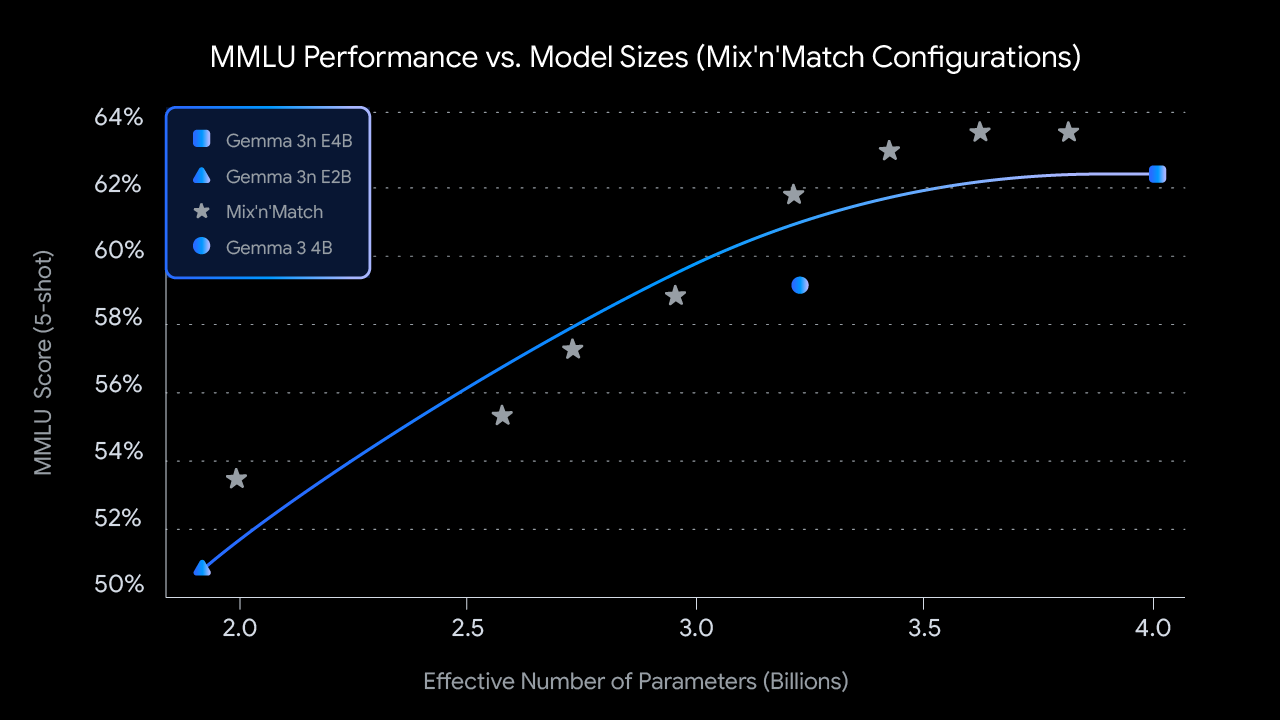
This graph shows the MMLU performance and model size for Gemma 3n’s mix-and-match (pre-training) feature.
Unlock new experiences on the go
Gemma 3n powers a new wave of intelligent on-the-go applications by enabling developers to:
Build live, interactive experiences that understand and respond to real-time visual and auditory cues from the user’s environment.
2. Combine audio, images, video, and text input to enhance deeper understanding and contextual text generation. Everything is done privately on your device.
3. Develop advanced audio-centric applications, including real-time transcription, translation, and voice-rich interactions.
Here’s an overview and the types of experiences you can build:
Build together responsibly
Our commitment to responsible AI development is paramount. Gemma 3n, like all Gemma models, has undergone rigorous safety assessments, data governance and fine-tuning with our safety policies. We approach our open model with careful risk assessment and are continually refining our practices as the AI landscape evolves.
Get started: Preview Gemma 3n now
We’re looking forward to bringing Gemma 3n to you through previews starting today.
Initial access (currently available):
Cloud-based exploration with Google AI Studio: Try Gemma 3n directly in your browser in Google AI Studio. No setup required. Try out the text input feature right away. On-device development with Google AI Edge: For developers looking to integrate Gemma 3n locally, Google AI Edge provides tools and libraries. You can start using text and image understanding/generation features today.
Gemma 3n represents the next step in democratizing access to cutting-edge, efficient AI. We’re excited to see what you build as we gradually make this technology available, starting with today’s preview.
This announcement and all Google I/O 2025 updates will be available on io.google starting May 22nd.
