


Earlier this year, AMD and Haggingface announced a partnership to accelerate AI models during AMD’s AI day event. We have worked hard to bring this vision to reality and ensure that the embracing face community can run the latest AI models on AMD hardware at the best possible performance.
AMD powers some of the world’s most powerful supercomputers, including the fastest European Lumi, surpassing the 10,000 MI250X AMD GPU. At this event, AMD revealed its latest generation of server GPUs, the AMD Instinct™ MI300 Series Accelerator.
This blog post provides excellent box-out box support for AMD GPUs and provides up-to-date information on progress to improve interoperability with the latest server-grade AMD Instinct GPUs.
Accelerate the box immediately
Can I find the following AMD-specific code changes? Don’t hurt your eyes, not compared to running with Nvidia GPUS.
from transformer Import AutoTokenizer, AutomodelForcausallum
Import Torch Model_id = “01-AI/YI-6B”
Tokenizer = autotokenizer.from_pretrained(model_id)
and torch.device (“cuda”): model = automodelforcausallm.from_pretrained(model_id, torch_dtype = torch.float16)inp = tokenizer((())“I’m in Paris today.”), Paddy=truthreturn_tensors =“PT”). In (“cuda”)res = model.generate(**inp, max_new_tokens =30))
printing(tokenizer.batch_decode(res))
One of the main aspects we have been working on is the ability to run face trans models that hug without changing the code. Currently, it supports all transformer models and tasks for AMD Instinct GPUs. Also, collaboration has not stopped here as we are investigating box-out box support for diffuser models, other libraries, and other AMD GPUs.
Achieving this milestone was a critical effort and collaboration between the team and the company. To maintain support and performance of the embracing face community, we have built an integration test that hugged the AMD Instinct GPU face open source library in our data center. And we were able to minimize the carbon impact of these new workloads that work with Verne Global to deploy AMD instinct servers in Iceland.
In addition to native support, another major aspect of our collaboration is offering the latest innovations and feature integrations available on AMD GPUs. Through collaboration between Face Team, AMD engineers and open source community members, we are pleased to announce the following support:
We are very excited to make these cutting-edge acceleration tools available and easy to use to embrace face users, providing support and performance directly integrated into the new continuous integration and development pipeline of AMD instinct GPUs.
One AMD instinct MI250 GPU with 128 GB of high bandwidth memory has two different ROCM devices (GPU 0 and 1), each with 64 GB of high bandwidth memory.
This means that you can have just one MI250 GPU card and two Pytorch devices that are extremely easy to use with tensor and data parallelism, providing higher throughput and lower latency.
The rest of the blog post reports performance results for two related steps during text generation through a large language model.
Prefill Latency: The amount of time it takes for a model to calculate the representation of a user’s provided input or prompt (also known as “time to the first token”). Decode per token latency: The amount of time it takes to generate a new token using the auto-escaping method after a prefill step. Throughput Decode: The number of tokens generated per second during the decoding phase.
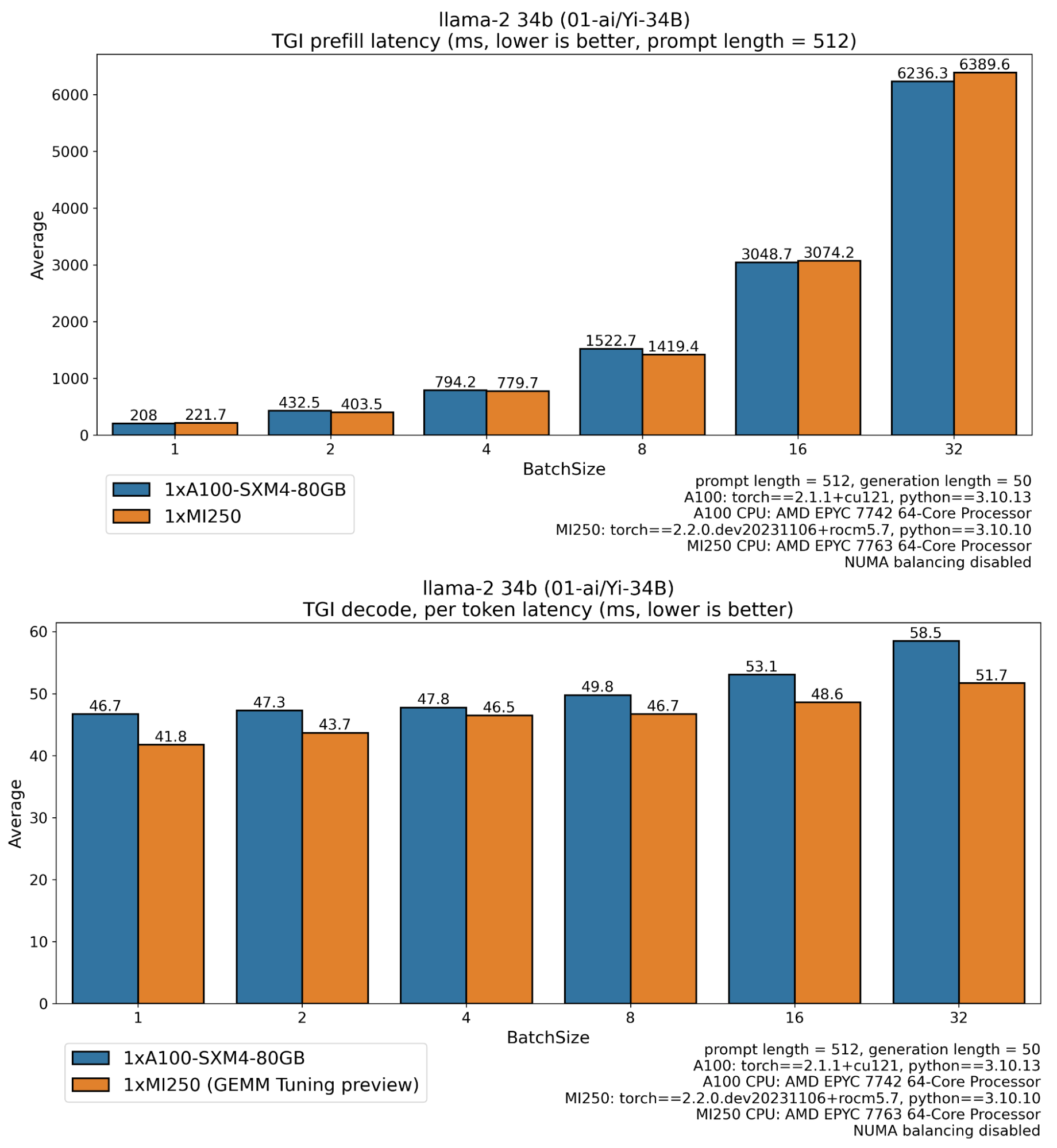
Using optimal benchmarks and execution inference benchmarks on A100 GPUs with and without MI250 and optimization, you can get the following results:
In the plot above, you can see how well the MI250 performs, especially in a production setting where requests are processed in large batches, providing over 2.33 times the token (decode throughput), and half the time for the first token (prefill latency) compared to the A100 card.
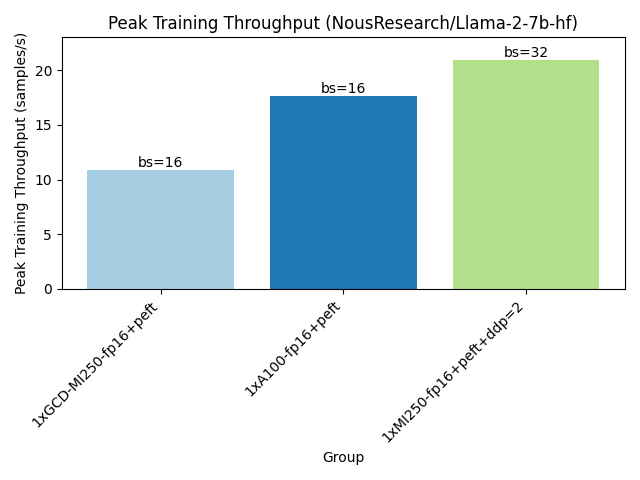
Running the training benchmark as shown below will allow one MI250 card to fit a larger batch of training samples, reaching a higher training throughput.
Production Solutions
Another important focus of our collaboration is to start with text generation inference (TGI) and build support to embrace facial production solutions. TGI offers an end-to-end solution for deploying large language models for scale inference.
Initially, TGI was driven primarily towards Nvidia GPUs and took advantage of most of the recent optimizations made for postampere architectures, including Flash Attention V1 and V2, GPTQ weight quantization, and paging attention.
Today we announced initial support for TGI’s AMD Instinct MI210 and MI250 GPUs, leveraging all the great open source work mentioned above, and are ready to be integrated into a complete end-to-end solution.
On the performance side, I spent a lot of time benchmarking text generation inferences on AMD Instinct GPUs, examining and discovering where the focus should be on optimization. Therefore, with the support of AMD GPUS engineers, we were able to achieve matching performance compared to what TGI already had.
In this context, we have built a long-term relationship between our embraced faces with AMD, so we’re integrating and testing it with the AMD GEMM tuner tool that allows us to find the best setup for improved performance to tune the GEMM (Matrix Multiplication) kernel we use in TGI. The GEMM Tuner Tool is scheduled to be released as part of Pytorch.
With all of the above being said, we are excited to showcase the first performance numbers that show the latest AMD technology. It places text-generating inference on AMD GPUs at the forefront of efficient inference solutions with the LLAMA model family.
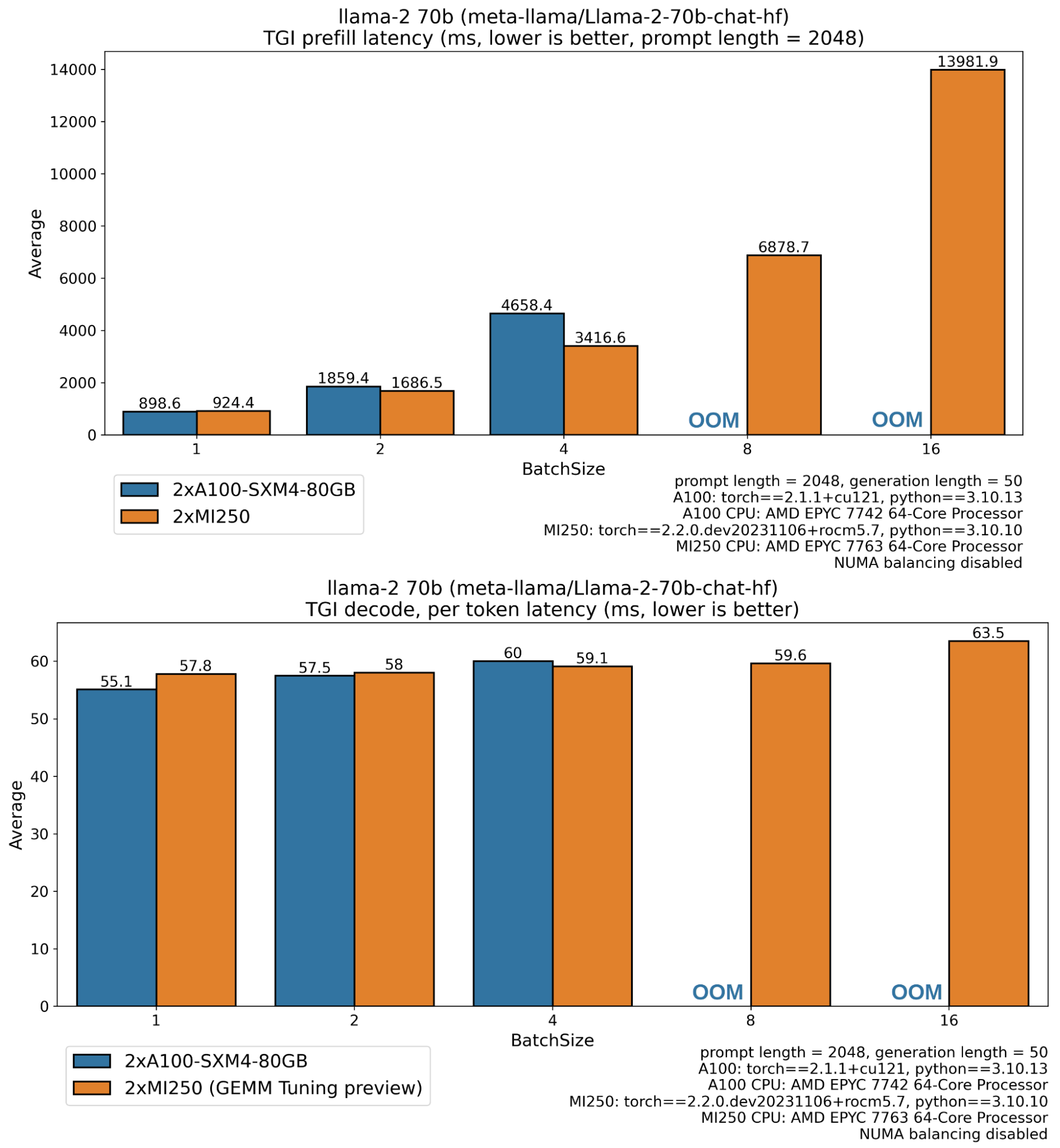
The missing bar on the A100 is on llama 70b weights 138 gb in float16, so it handles out-of-memory errors and requires sufficient free memory for intermediate activation, kv cache buffers (>5gb with 2048 sequence length, batch size 8, cuda context, etc.). MI250 sequence, big batch).
Text generation inference is ready for deployment during production on AMD Instinct GPU via Docker Image ghcr.io/huggingface/text-generation-inference:1.2-ROCM. Be sure to refer to the support and its limitations documentation.
What’s next?
I hope this blog post is just as exciting as I have a face to face about this partnership with AMD. Of course, this is just the beginning of our journey and we look forward to enabling more use cases with more AMD hardware.
We are committed to bringing support and validation of AMD Radeon GPUs over the next few months. AMDRadeonGPU can be placed on its own desktop for local use, lowering the barrier to accessibility and paving the way for even more versatility for users.
Of course, we’ll be working on performance optimizations for our MI300 lineup right away, ensuring that both open source and solutions deliver the latest innovations at the highest level of stability we’ve always hugged.
Another area of focus for us is around AMD Ryzen AI technology, powered by the latest generation of AMD laptop CPUs, allowing AI to run on the edge on devices. As coding assistants, image generation tools and personal assistants become more and more widely available, it is important to provide solutions that can meet your privacy needs to leverage these powerful tools. In this context, Ryzen AI-compatible models are already available on the facehub of Hugs and are working closely with AMD to bring more in the coming months.
