


Update (November 2024): The integration is no longer available. Switch to the inference API, inference endpoint, or other deployment options for hugging faces, depending on your AI model’s needs.
Today, we are excited to announce the launch of Deploy for CloudFlare Workers AI, a new integration for Hugging Face Hub. Deployed to CloudFlare Workers AI easily uses the open model as a serverless API with cutting-edge GPUs deployed in CloudFlare Edge data centers. Starting today, we’ve integrated some of the most popular open models that will hug your face to CloudFlare Worker AI with production solutions, including text generation inference.
Deploying CloudFlare Worker AI allows developers to build robust, generated AI applications without managing GPU infrastructure and servers, with very low operating costs.
Generated AI for developers
This new experience expands the strategic partnership that was announced last year to simplify access and deployment of open-generated AI models. One of the main issues faced by developers and organizations is the scarcity of GPU availability and the fixed cost of deploying servers to start buildings. CloudFlare Worker Deployment AI offers easy, low-cost solutions to these challenges, providing serverless access to popular embrace face models.
Let’s take a look at a concrete example. Imagine developing a RAG application that gets ~1000 requests per day and developing a 1K token input and a 100 token output using Meta Llama 2 7b. The production cost of LLM inference is approximately $1 per day.
“We look forward to achieving this integration very quickly. By putting the power of CloudFlare’s global network of serverless GPUs into the hands of developers, we are opening the door to many exciting innovations by communities around the world.”
How it works
It’s very easy to use embracing face models with CloudFlare Worker AI. Below are step-by-step instructions on how to use the Hermes 2 Pro with the latest model from Nous Research, the Mistral 7b.
You can find all the models available in this CloudFlare collection.
Note: You will need to access your CloudFlare account and API tokens.
You can find CloudFlare deployment options on all available model pages, including models such as Llama, Gemma, Mistral, and more.
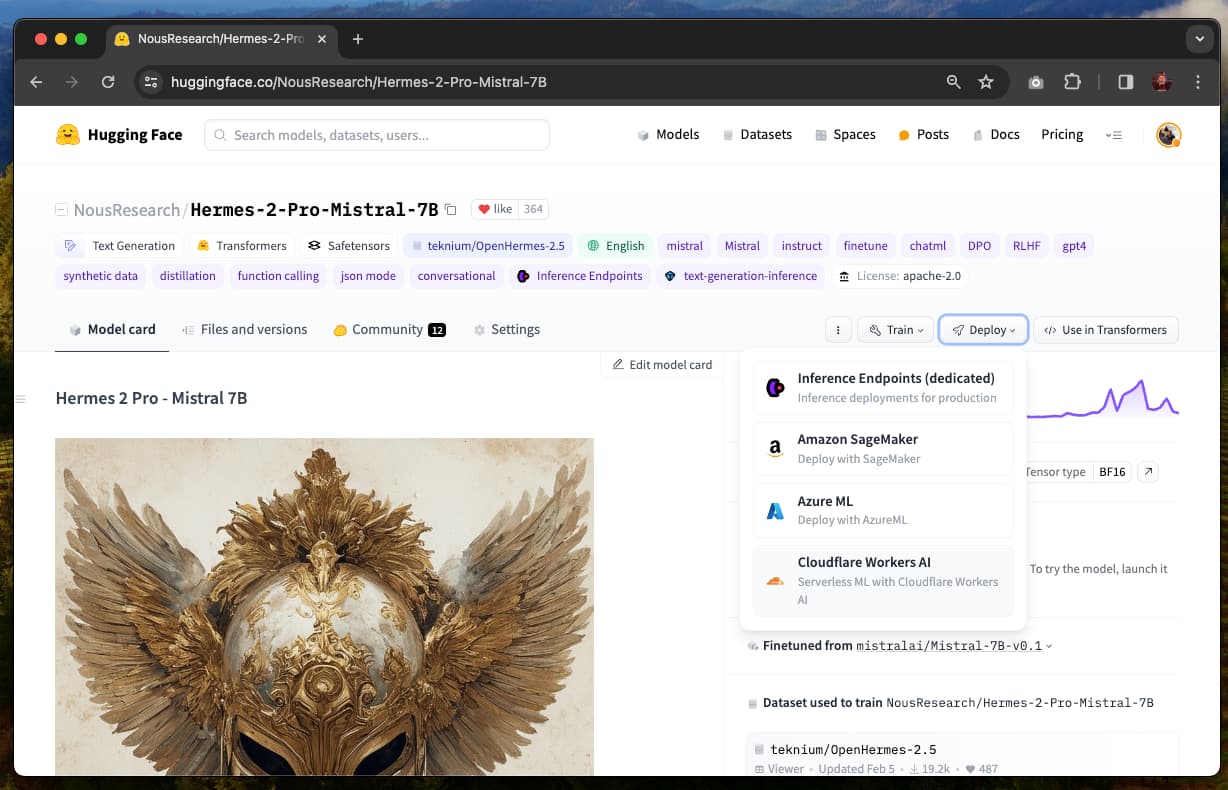
Open the Deployment menu and select CloudFlare Workers AI. This opens an interface on how to use this model and how to send requests.
Note: If the model you are using does not have the “CloudFlare Workers AI” option, it is currently not supported. We are working with CloudFlare to increase the availability of our models. Please contact us using your request at api-enterprise@huggingface.co.
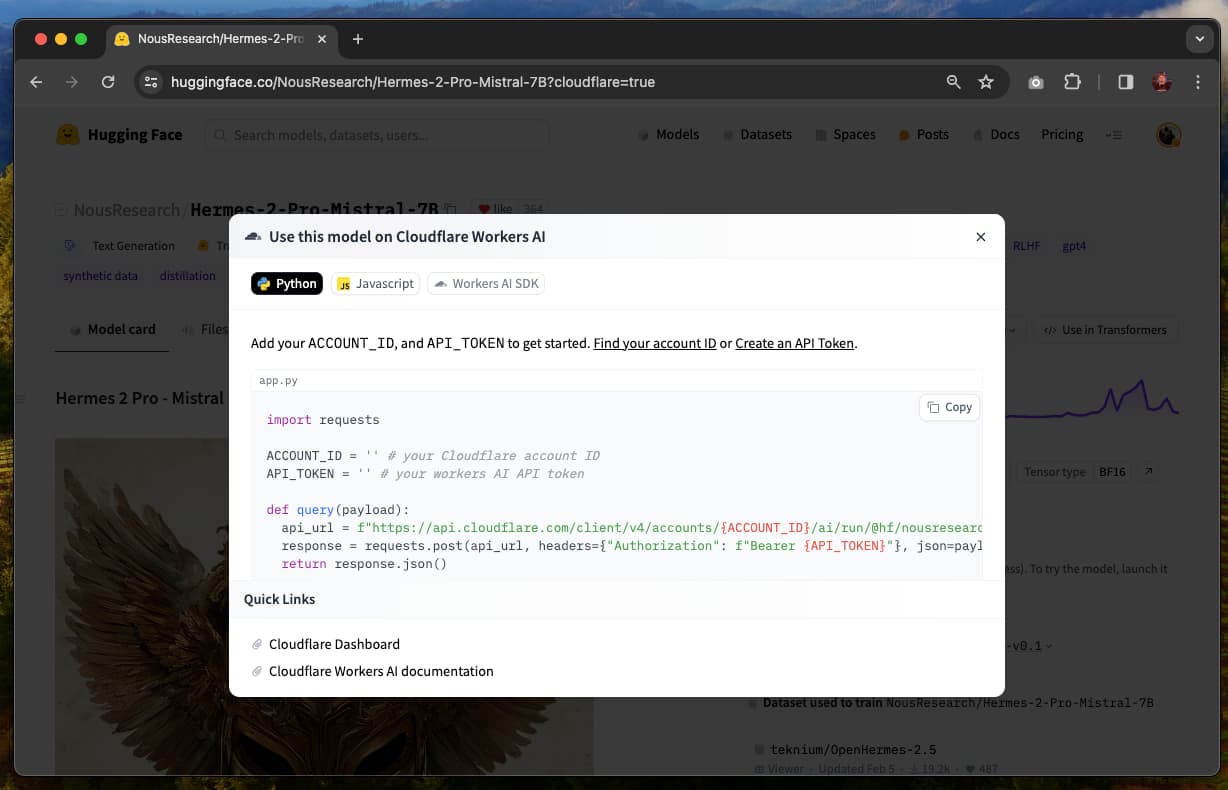
Currently, integration is available through two options. It can be used directly by workers using the Worker AI REST API or using the CloudFlare AI SDK. Select the option you want and copy the code to your environment. When using the REST API, you must ensure that the Account_ID and API_TOKEN variables are defined.
that’s it! You can now begin sending requests to hug face models hosted by CloudFlare Worker AI. Make sure to use the correct prompts and templates that your model expects.
I’ve just started
We are excited to work with CloudFlare to make AI more accessible for developers. Work with the CloudFlare team to make more models and experiences available!
