


Whisper is one of the best open source speech recognition models and is undoubtedly the most widely used one. It’s very easy to unfold the whispering model from the box by hugging the endpoint of face reasoning. However, things can be more tricky if you want to showcase additional features such as a dialization pipeline to identify speakers, or help generate them for speculative decoding. The reason is that whispers and additional models must be combined while exposing a single API endpoint.
This issue is solved using a custom inference handler. Custom inference handlers implement automatic speech recognition (ASR) and dialization pipelines on inference endpoints to support speculative decoding. The implementation of the dialization pipeline is inspired by the well-known insanely fast whispers, using the pyannote model for dialization.
This also shows how flexible the endpoint of flexibility inference is, and that almost anything can be hosted there. Here’s the code to follow: Note that the entire repository is mounted during endpoint initialization, so handler.py can refer to other files in the repository if you don’t want all the logic to a single file. In this case, I decided to separate things into several files to keep things clean.
Handler.py contains the initialization and inference code Diarization_utils.py. ModelSettings defines the model used in the pipeline (you don’t need to use everything), and deferenceConfig defines the default inference parameters
Starting with Pytorch 2.2, SDPA supports Flash Attention 2-Off-Off-Box, so we use that version for faster inference.
Main Module
This is a high-level diagram of what the endpoint looks like under the hood.
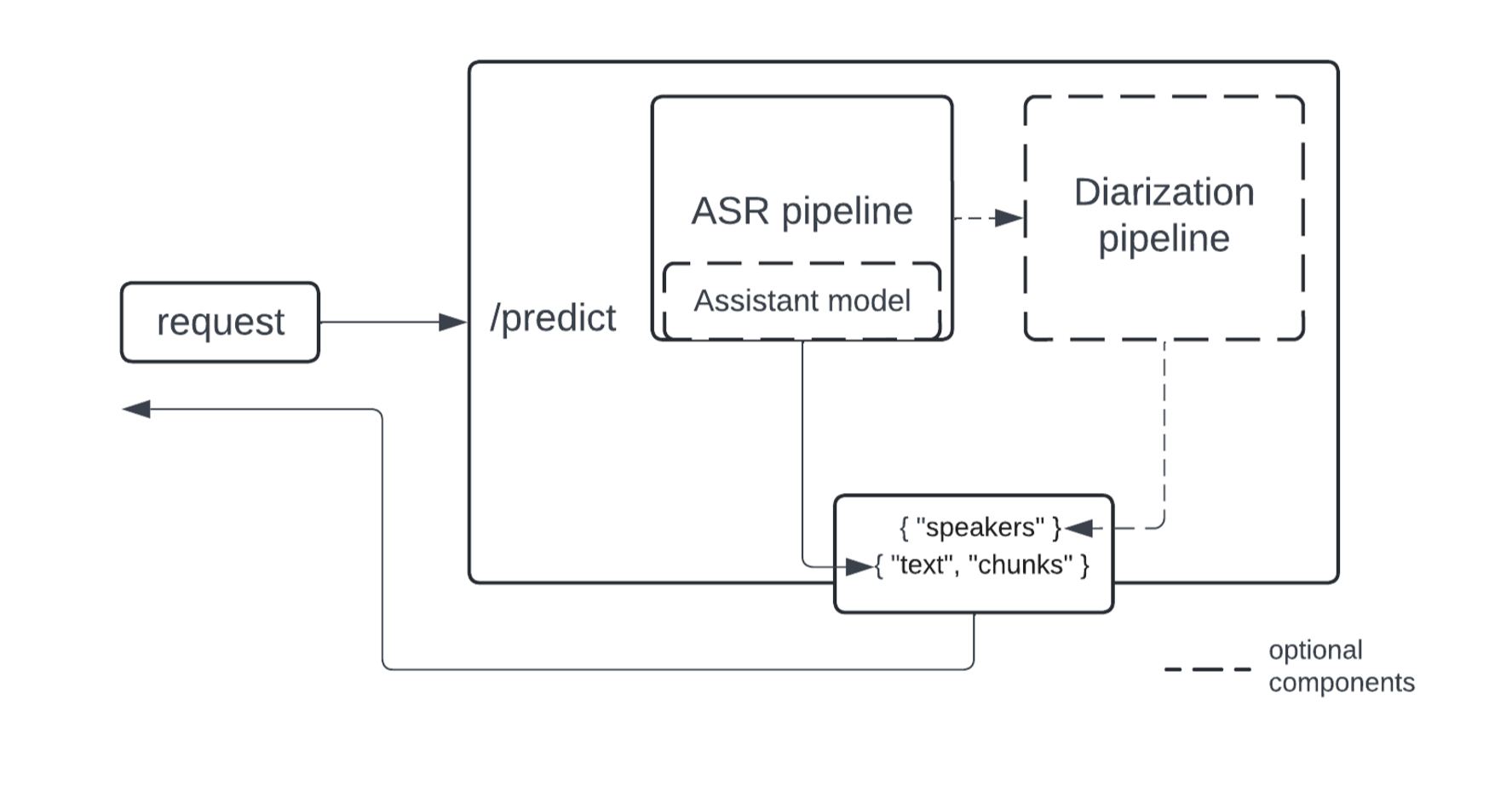
The implementation of ASR and Dialysis Pipelines is modularized to accommodate a wider range of use cases – the Dialysis pipeline runs on top of ASR output and only ASR parts can be used if no Diaration is required. Dialyization is proposed using the Pyannote model, which is currently an implementation of SOTA open source.
It also adds speculative decoding as a way to speed up inference. Speed-up is achieved by using smaller and faster models to suggest generations validated by larger models. In this great blog post, please go into detail about how it works, especially with Whisper.
Speculative decoding is limited.
At least the decoder part of the assistant model must have the same architecture as the main model.
Consider the above. Depending on the production use case, supporting larger batches can be faster than speculative decoding. If you don’t want to use an assistant model, don’t leave Assistant_Model to configuration.
When using the assistant model, the best choice for Whisper is the distilled version.
Set your own endpoint
The easiest way to get started is to clone a custom handler repository using repository duplication.
Here is the model load piece from Handler.py:
from pyannote.audio Import Pipeline
from transformer Import Pipeline, automodelforcausallm … self.asr_pipeline = pipeline (
“Automatic Speech – Recognition”,Model = model_settings.asr_model, torch_dtype = torch_dtype, device = device)self.assistant_model = automodelforcausallm.from_pretrained(model_settings.assist_model, torch_dtype = torch_dtype, low_cpu_mem_usage =truth,use_safetensors =truth
)… self.diarization_pipeline = pipeline.from_pretrained(checkpoint_path = model_settings.diarization_model, use_auth_token = model_settings.hf_token,)…
You can customize your pipeline based on your needs. The Modelsettings in the config.py file holds the parameters used for initialization and defines the model to use during inference.
class Model set(Base setting): asr_model: str
Assistant_model: option(str)= none
diarization_model: option(str)= none
hf_token: option(str)= none
Parameters can be adjusted by passing through environment variables with corresponding names. This works with both custom containers and inference handlers. This is a characteristic of the Pidan faction. To pass environment variables to the container during build time, you must create an endpoint via an API call (not an interface).
Instead of passing the model name as an environment variable, you can hardcode the model name, but note that in the dialization pipeline you must explicitly pass the token (HF_TOKEN). Hardcode tokens for security reasons is not permitted. This means that you need to create the endpoint via API calls to use the dialization model.
As a reminder, all dialization-related pre-processing and post-processing utils can be found in diarization_utils.py
The required components are the ASR model. Optionally, you can specify an assistant model to use for guess decoding, and you can use the dialization model to split the transcription by the speaker.
Expand to the inference endpoint
If you only need ASR parts, you can expand it by specifying asr_model/assistant_model in config.py and clicking the button.
To pass environment variables to containers hosted by inference endpoints, you must programmatically create the endpoint using the provided API. Below is an example.
body = {
“Calculation”:{
“accelerator”: “GPU”,
“Instantiation”: “Medium”,
“InstanceType”: “g5.2xlarge”,
“scaling”:{
“Maxreplica”: 1,
“Minreplica”: 0
}},
“Model”:{
“Framework”: “Pytorch”,
“image”:{
“Hugging Face”:{
“env”:{
“HF_MODEL_DIR”: “/Repository”,
“diarization_model”: “pyannote/speaker-diarization-3.1”,
“HF_TOKEN”: “”,
“asr_model”: “Openai/Whisper-Large-V3”,
“assistan_model”: “Distillation/Distillation-large-v3”
}}},
“Repository”: “Sergeipetrov/Asrdiarization Handler”,
“task”: “custom”
},
“name”: “ASR-Diarization-1”,
“Provider”:{
“region”: “US-East-1”,
“vendor”: “AWS”
},
“type”: “Private”
}
When to use the assistant model
Here is the benchmarks performed in K6 to give you a better idea of when it is beneficial to use the assistant model:
asr_model = openai/whisper-large-v3 assistant_model = distil-whisper/distil-large-v3 long_assisted …..: avg = 4.15s min = 3.84s med = 3.95s max = 6.88sp(90) = 4.03sp(95) = 4.89s length_not_assisted min = 3.42S MED = 3.46S MAX = 3.71SP(90) = 3.56SP(95) = 3.61S SHORT_ASSISTED …..: AVG = 326.96MS MIN = 313.01MS MED = 319.41MS MAX = 960.75ms P(90) = 325.555555555MS = 326.07ms AVG = 784.35ms min = 736.55ms med = 747.67ms max = 2s p(90) = 772.9ms p(95) = 774.1ms
As you can see, when the audio is short, Assisted Generation offers dramatic performance improvements (batch size is 1). If the audio is long, inference will automatically be charged to batches, and speculative decoding can damage inference time due to the limitations discussed previously.
Inference parameters
All inference parameters can be found in config.py:
class IsmerenceConfig(Base model): Task: literal(“Transfer”, “Translate”)= “Transfer”
batch_size: int = twenty four
assist: Boolean = error
chunk_length_s: int = 30
sampling_rate: int = 16000
language: option(str)= none
num_speakers: option(int)= none
min_speakers: option(int)= none
max_speakers: option(int)= none
Of course, you can add or remove parameters if you wish. Parameters related to the number of speakers are passed to the dialization pipeline, but everything else is mostly for the ASR pipeline. sampling_rate indicates the sampling rate of the audio to be processed and is used for preprocessing. The support flag tells the pipeline whether speculative decoding is used. Remember that for assisted generation, batch_size must be set to 1.
payload
Once unfolded, send the inference parameters along with the inference parameters to the inference endpoint, like in this (Python).
Import base64
Import Request API_URL = “”
filepath = “/path/to/audio”
and open(filepath, “RB”)) As F:audio_encoded = base64.b64encode(f.read()). Decode (“UTF-8”)data = {
“input”:audio_encoded,
“parameter”:{
“batch_size”: twenty four
}} resp = requests.post(api_url, json = data, headers = {“Approval”: “Bearer”})
printing(resp.json())
Here, the “Parameters” field is a dictionary containing all the parameters to adjust from the recommendations. Note that parameters not specified in IsmerenceConfig will be ignored.
Or you need inference (there is an asynchronous version too):
from huggingface_hub Import Inference client = Inference client (model = “”token =“”))
and open(“/path/to/audio”, “RB”)) As F:audio_encoded = base64.b64encode(f.read()). Decode (“UTF-8”)data = {
“input”:audio_encoded,
“parameter”:{
“batch_size”: twenty four
}} res = client.post(json = data)
summary
In this blog, we discussed how to set up a speculative decode pipeline with modular ASR + diarization + embracing face inference endpoints. We did our best to make it easy to configure and adjust the pipeline as needed. Deployment using inference endpoints is always cake! We are fortunate to have great models and tools that the community used in our implementation can openly utilize.
I have a repository that implements the same pipeline along with the server parts (Fastapi+Uvicorn). It may be useful if you want to customize more or host it somewhere.
