



The Stable Diffusion XL released yesterday is amazing. It can generate large (1024×1024) high quality images. Several new tricks have improved adherence to prompts. Thanks to the latest research in noise schedulers, you can easily generate very dark or very bright images. And it’s open source!
The downside is that the model is much larger, making it slower and more difficult to run on consumer hardware. The latest release of the Hugging Face diffuser library allows you to run Stable Diffusion XL on CUDA hardware with 16 GB of GPU RAM, making it available on Colab’s free tier.
Over the past few months, we’ve seen a very clear interest in people running ML models locally for a variety of reasons, including privacy, convenience, ease of experimentation, and pay-as-you-go usage. We’ve been working hard to explore this space at both Apple and Hugging Face. We showed you how to run Stable Diffusion on Apple Silicon, or leverage the latest advances in Core ML to increase size and performance with 6-bit palletization.
With Stable Diffusion XL, we did a few things.
Ported the base model to Core ML so it can be used in native Swift apps. We’ve updated Apple’s Transformation and Inference repository to include tweaks you might be interested in so you can transform the model yourself. We’ve updated the Hugging Face demo app to demonstrate how to use the new Core ML Stable Difffusion XL model downloaded from the hub. We considered mixed-bit palletization, an advanced compression technique that achieves significant size reductions while minimizing the quality loss incurred. You can apply the same technique to your own models.
Everything is open source and available today, so get started.
content
Using the SD XL Model from the Hug Face Hub
As part of this release, we published two different versions of Stable Difffusion XL for Core ML.
Both models can be tested using Apple’s Swift command-line inference app or Hugging Face’s demo app. Here’s an example of the latter using the new Stable Diffusion XL pipeline.
As with previous Stable Diffusion releases, we expect the community to come up with new and fine-tuned versions for different domains, many of which will be converted to Core ML. Check out this filter in the hub to explore.
Stable Diffusion XL runs on Apple Silicon Macs running the public beta version of macOS 14. We are currently using the original Attention implementation, which targets CPU + GPU compute units. Please note that the refiner stage has not yet been ported.
For reference, here are the performance numbers achieved on various devices.
Device –compute-unit –attention-implementation End-to-end Latency (sec) Spread Rate (iter/s) MacBook Pro (M1 Max) CPU_AND_GPU ORIGINAL 46 0.46 MacBook Pro (M2 Max) CPU_AND_GPU ORIGINAL 37 0.57 Mac Studio (M1 Ultra) CPU_AND_GPU ORIGINAL 25 0.89 Mac Studio (M2 Ultra) CPU_AND_GPU Original 20 1.11
What is mixed bit palletization?
Last month, we discussed 6-bit palletization, a post-training quantization technique that transforms 16-bit weights into just 6 bits per parameter. Although this achieves a significant reduction in model size, it is difficult to exceed it since the impact on model quality becomes increasingly large as the number of bits decreases.
One option to further reduce model size is to use training-time quantization, which learns a quantization table while fine-tuning the model. This works well, but requires a fine-tuning phase to be performed for each model you convert.
We instead considered another alternative: mixed bit palletization. Instead of using 6 bits per parameter, examine your model to determine how many quantization bits to use per layer. Base your decision on how much each layer contributes to the overall quality degradation. This is measured by comparing the PSNR between the quantized model and the original model in float16 mode for some set of inputs. For each layer, we look at several bit depths: 1 (!), 2, 4, and 8. For example, if you are using 2 bits and your layers degrade significantly, move to 4 bits and so on. Some layers may be kept in 16-bit mode if important to maintain quality.
Using this method, we can achieve, for example, an effective quantization of 2.8 bits on average, and measure the impact on degradation for every combination we try. This will give you better information about the best quantization to use for your target quality and size budget.
To illustrate this method, consider the following quantization “recipe” from one of the analysis runs (we will discuss how the recipe was generated later).
{
“Model_Version”: “stabilityai/stable-diffusion-xl-base-1.0”,
“Baseline”: {
“original”: 82.2,
“Linear_8 bit”: 66.025,
“Recipe_6.55_Bit_Mix Palette”: 79.9,
“Recipe_4.50_Bit_Mix Palette”: 75.8,
“Recipe_3.41_Bit_Mix Palette”: 71.7,
},
}
This indicates that the quality of the original model as measured by the PSNR of float16 is approximately 82 dB. Performing a simple 8-bit linear quantization drops it to 66 dB. However, there is a recipe that compresses it to an average of 6.55 bits per parameter while keeping the PSNR at 80 dB. The second and third recipes further reduce the model size while maintaining a higher PSNR than 8-bit linear quantization.
As a visual example, below is the result of prompting a high-quality photo of a surfing dog running each of three recipes using the same seed.
3.41 bit 4.50 bit 6.55 bit 16 bit (original)




The first conclusion is:
In our opinion, all images have excellent quality in terms of how realistic they look. In this respect, the 6.55 and 4.50 versions are similar to the 16-bit versions. The same seed will produce equivalent configurations, but they will not retain the same details. For example, dogs may be of different breeds. Increasing compression may reduce compliance with prompts. In this example, the aggressive 3.41 version loses the board. PSNR only compares how different pixels are overall and does not take into account the subject matter in the image. You should examine the results and evaluate them for your use case.
This technique is ideal for Stable Diffusion XL because it allows you to maintain approximately the same UNet size even when the number of parameters triples compared to the previous version. But it’s not limited to that! This method can be applied to any Stable Diffusion Core ML model.
How is a mixed bits recipe made?
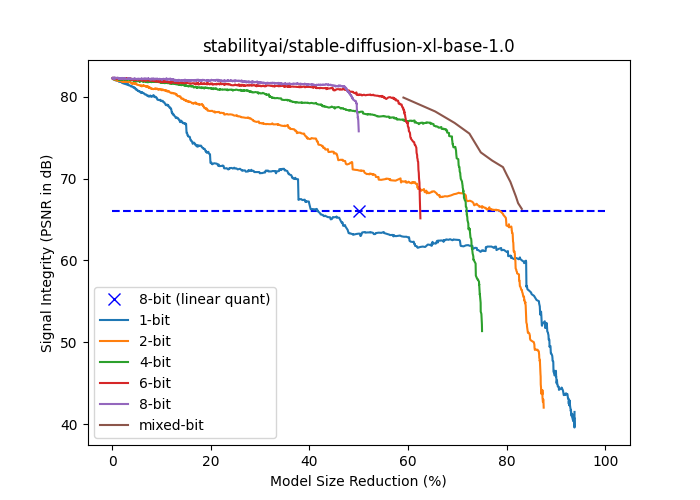
The following plot shows the signal strength (PSNR in dB) and model size reduction (% of float16 size) for stabilityai/stable-diffusion-xl-base-1.0. The {1,2,4,6,8} bit curve is generated by progressively palletizing more layers using a fixed number of bits palette. The layers are ordered in ascending order of their isolated contributions to end-to-end signal strength, so that the cumulative compression impact is delayed as much as possible. The mixed bit curve is based on falling back to a higher number of bits as soon as the layer’s separated impact on end-to-end signal integrity falls below a threshold. Note that all curves based on palletization perform better than linear 8-bit quantization for the same model size, except for 1 bit.
Mixed-bit palletization is performed in two phases: analysis and application.
The goal of the analysis phase is to find a point in the mixed bit curve (the brown point above all other points in the diagram) so that you can choose the desired quality-size tradeoff. As described in the previous section, we iterate through the layers to choose the lowest bit depth that yields results above a certain PSNR threshold. Repeat this process for different thresholds to obtain different quantization strategies. Therefore, the result of the process is a set of quantization recipes. Each recipe is simply a JSON dictionary that details the number of bits to use for each layer in the model. Layers with few parameters are ignored and kept in float16 for simplicity.
The application phase simply examines the recipe and applies palletization with the number of bits specified in the JSON structure.
Analysis is a long process and requires running inference multiple times, so GPUs (mps or cuda) are required. Once completed, applying the recipe can be done in minutes.
Scripts are provided for each of these phases.
Transforming a fine-tuned model
If you have previously converted a stable diffusion model to Core ML, the process for XL using the command line converter is very similar. There is a new flag that indicates whether the model belongs to the XL family, in which case –attention-implementation ORIGINAL must be used.
Check the steps in either the repo or previous blog post for an overview of the process and make sure to use the flags listed above.
Performing mixed bit palletization
After converting a Stable Diffusion or Stable Diffusion XL model to Core ML, you can optionally apply mixed-bit palletization using the script above.
Since the analysis process is time-consuming, we have prepared recipes for the most popular models.
You can download these and apply them locally to experiment.
Additionally, we applied the three best recipes from the stable diffusion XL analysis to the Core ML version of UNet and published them here. Feel free to play around with it and see how it works.
Finally, as mentioned at the beginning, we created a complete Stable Diffusion XL Core ML pipeline using a 4.5-bit recipe.
Published resources
