


I look forward to being able to present an efficient, non-spread text-to-image model named Amused. It is called so because it is an open replica of Google’s muse. Amused generation quality is not the best, and we release a research preview with a generous license.
In contrast to the commonly used potential diffusion approach (Rombach et al. (2022)), funness employs masked image model (MIM) methodology. This is not only a few inference procedures, as Chang et al points out. (2023) as well as the interpretability of the model is also improved.
Sohn et al, as Muse demonstrates the extraordinary ability of style transfer using a single image. (2023). This aspect could pave a new pathway to personalized style-specific image generation.
This blog post introduces the interior that is interesting, shows you how to use it for various tasks, including images from text, and shows you how to fine-tune it. Along the way, we provide all the important resources related to fun, including training codes. Let’s get started
table of contents
We have created a demo that will make readers play in an interesting way. You can try it in this space or in the playground embedded below.
How does it work?
Amused is based on masked image modeling. It becomes a compelling use case for communities to explore components known to work in linguistic modeling in the context of image generation.
The diagram below provides an outline of the picture of how fun works.
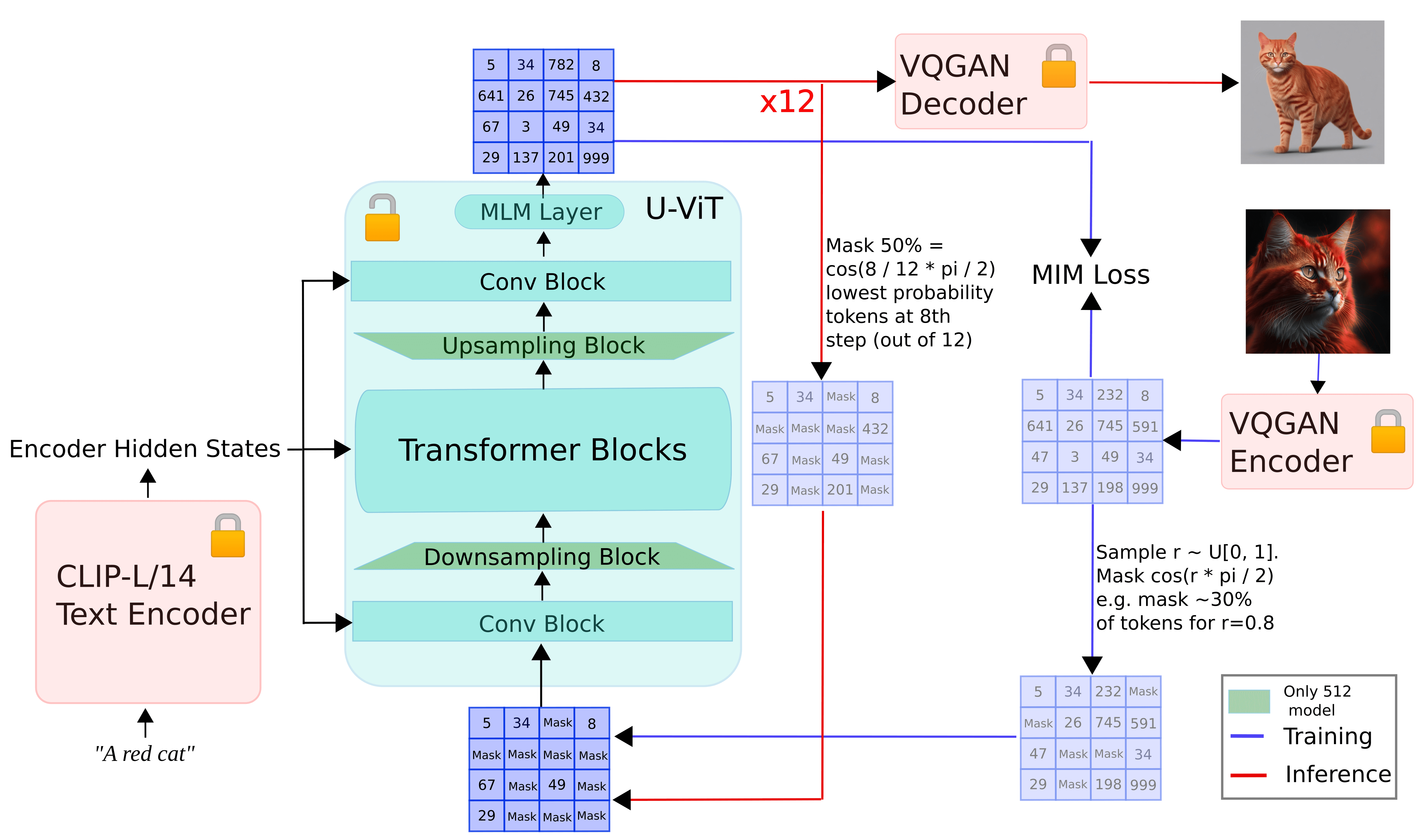
During training:
The input image is tokenized using VQGAN, image tokens are obtained, and image tokens are masked according to the Cosine masking schedule. Masked token (conditioned to prompt enmmming calculated using Clip-L/14 text encoder is passed to the U-vit model predicting masked patches
Inference:
The input prompt is built in using the CLIP-L/14 text encoder. Iterate until n step is reached. Starting with randomly masked tokens, we pass them to the U-vit model, along with embedding prompts to predict masked tokens, and maintain a certain percentage of the most confident predictions based on N and mask schedules. Mask the rest, pass them to the U-vit model, and pass the final output to the VQGAN decoder to get the final image
As mentioned at the beginning, it borrows many similarities from the muse, as amusingly. However, there are some notable differences.
Amuse does not follow a two-stage approach to predict the final masked patch. Instead of using T5 for text conditioning, Clip L/14 is used to calculate text embedding. Following stable diffusion XL (SDXL), additional conditioning such as image size and cropping is passed to U-vit. This is called “microconditioning.”
For more information about Amused, we recommend reading our technical report here.
It’s interesting with diffusers
Amused is fully integrated into Diffusers. To use it, you must first install the library.
PIP Installation -U Diffuser Accelerates Transformer -Q
Let’s start by generating an image from text:
Import torch
from Diffuser Import AmusedPipeline Pipe = AmusedPipeline.from_pretrained(
“Fun/Fun-512”variant =“FP16”torch_dtype = torch.float16)pipe = pipe.to(“cuda”)prompt = “Expressionist Style Mecha Robots from Shrimp Town”
negial_prompt = “Low quality, ugly”
image = pipe(prompt, negative_prompt = negative_prompt, generator = torch.manual_seed(0). image(0) image

You can see how num_inference_steps affects the quality of images under fixed seeds.
from diffusers.utils Import make_image_grid images =()
for Steps in (5, 10, 15): image = pipe(prompt, neutral_prompt = negative_prompt, num_inference_steps = step, generator = torch.manual_seed(0). image(0) Image.Append (Image) grid = make_image_grid(image, rows =1cols =3)grid

Importantly, its size is small (only around 800m parameters including text encoder and VQ-Gan), so what’s interesting is very fast. The diagram below illustrates a comparative study of inference latency for various models that is interesting.
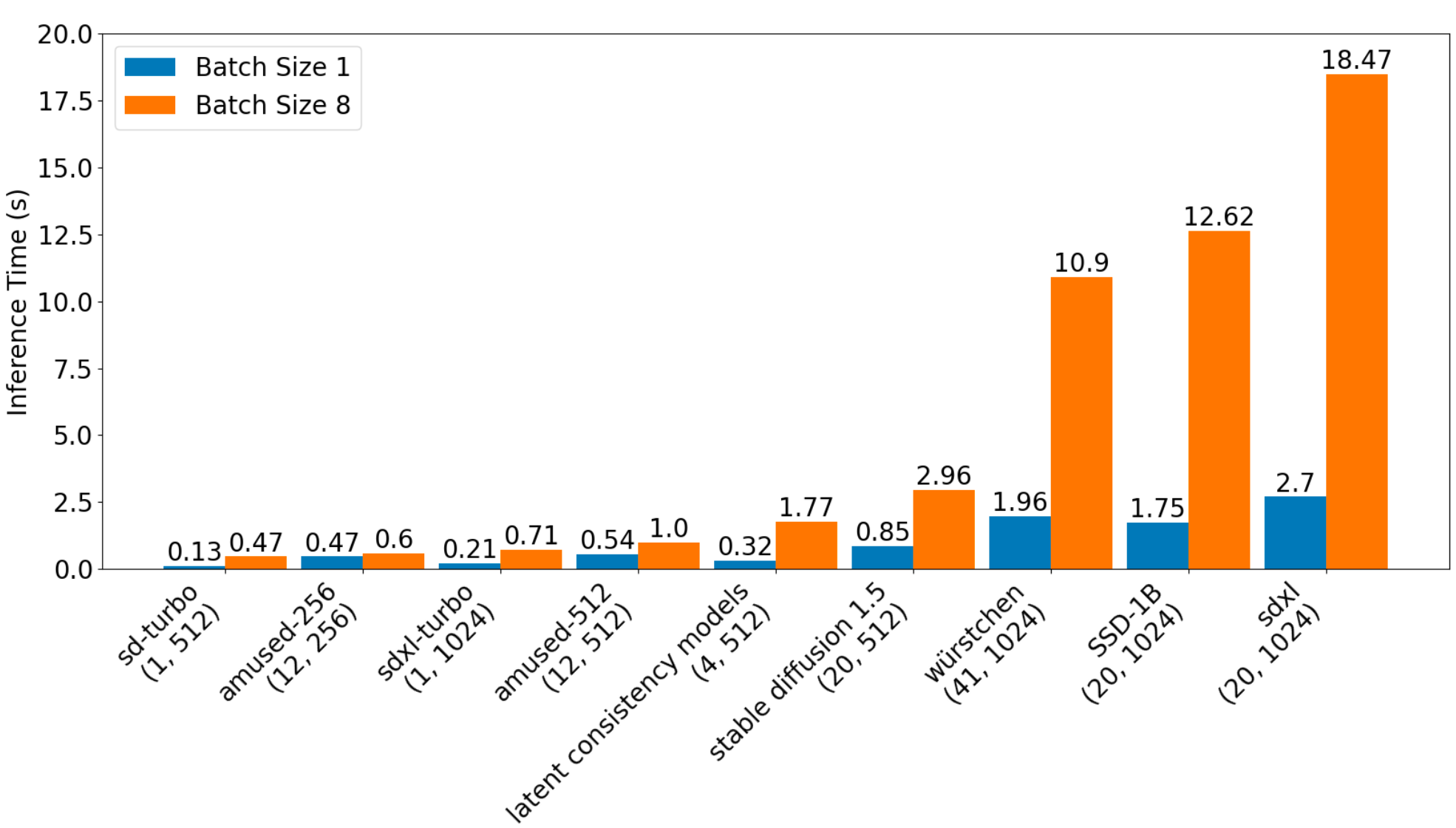
It’s interesting as a direct by-product of pre-training purposes, which makes it possible to run images that enter zero shots, unlike other models such as SDXL.
Import torch
from Diffuser Import Amusedinpaintpipeline
from diffusers.utils Import load_image
from pill Import Image pipe = amusedinpaintpipeline.from_pretrained(
“Fun/Fun-512”variant =“FP16”torch_dtype = torch.float16)pipe = pipe.to(“cuda”)prompt = “The man with glasses”
input_image =(load_image(
“https://huggingface.co/amused/amused-512/resolve/main/assets/inpainting_256_orig.png”
).resize((()512, 512)). Convert (“RGB”)) mask = (load_image(
“https://huggingface.co/amused/amused-512/resolve/main/assets/inpainting_256_mask.png”
).resize((()512, 512)). Convert (“L”)) image = pipe(prompt, input_image, mask, generator = torch.manual_seed(3). image(0))

Amused is the first non-diffusion system in a diffuser. Its iterative scheduling approach to predict masked patches has made it a great candidate for diffusers. I look forward to how the community will utilize it.
We recommend checking out our technical reports and learning about all the tasks you’ve researched in an interesting way.
The tweaks are interesting
Provides simple training scripts for fine-tuning with custom datasets. With the 8-bit Adam Optimizer and Float16 Precision, you can tweak it with just under 11GB of GPU VRAM. With LORA, your memory requirements are reduced to an additional 7GB.

Amused comes with an OpenRail license, so it’s commercially friendly to adapt. See this directory for more details on tweaking.
limit
What’s interesting is not the cutting edge image generation in terms of image quality. We have released Amused to encourage the community to explore non-spreading frameworks such as MIM for image generation. I consider Mim’s potential to be less revealing given its advantages.
Low inference efficiency and enables application task transfer on devices without the need for the benefits of expensive fine-tuning of well-established components from the world of language modeling
(Note that Muse’s original works are packed together.)
See the Technical Report for a detailed explanation of quantitative evaluation of fun.
We hope that the community feels the resources are useful and motivated to improve the state of MIM for image generation.
resource
paper:
Code + Other:
Acknowledgments
Suraj led the training. William led the data and supported the training. Patrick Von Platen supported both training and data and provided general guidance. Robin Ronbach did VQGAN training and provided general guidance. Isamu Isozaki helped with insightful discussions and made the code contributions.
Thank you to Patrick Von Platen and Pedro Cuenca for reviewing the blog post draft.
