

We aim to give you a clear overview of the advantages and disadvantages of each quantization scheme supported by Transformers, so that you can decide which one you should choose.
Currently, quantization models are used for two main purposes.
Run inference for large models on small devices Fine-tune adapters based on quantized models
To date, two integration efforts have been made and supported natively in Transformers: bitsandbytes and auto-gptq. 🤗 Please note that the Optimal Library also supports additional quantization schemes, but this is outside the scope of this blog post.
For more information about each supported scheme, please see one of the resources shared below. Please also refer to the appropriate section of the documentation.
Also note that the details shared below are only valid for PyTorch models, which is currently outside the scope of Tensorflow and Flax/JAX models.
table of contents
resource
Comparison of bitsandbytes and auto-gptq
This section describes the pros and cons of bitsandbytes and gptq quantization. Please note that these are based on community feedback and some of these features are in each library’s roadmap, so they may evolve over time.
What are the advantages of bit sand bite?
easy: bitsandbytes remains the easiest way to quantize any model, as it does not require adjusting the quantized model with the input data (also known as zero-shot quantization). You can quantize any model out of the box as long as it includes the torch.nn.Linear module. Whenever a new architecture is added to the transformer, users can immediately benefit from bit-sand-byte quantization with minimal performance degradation, as long as it can be loaded with device_map=”auto” on the accelerator. Quantization is performed when the model is loaded, so there is no need to perform any post-processing or preparation steps.
Cross-modality interoperability: The only condition to quantize a model is to include a torch.nn.Linear layer, so quantization works out of the box with any modality, allowing models like Whisper, ViT, and Blip2 to be loaded in 8-bit or 4-bit out of the box.
There is no performance penalty when merging adapters: (If you are not familiar with adapters and PEFT, read more about adapters and PEFT in this blog post). If you train your adapter on a quantized base model, you can merge the adapter onto the base model for deployment without degrading inference performance. You can also merge adapters on top of dequantized models. This is not supported by GPTQ.
What are the benefits of autoGPTQ?
Faster text generation: The GPTQ quantization model has faster text generation compared to the bit-sandbyte quantization model. Speed comparisons are discussed in the appropriate sections.
n-bit support: The GPTQ algorithm allows you to quantize your model up to 2 bits. However, this may come with a significant loss in quality. The recommended number of bits is 4, but this seems like a big trade-off for GPTQ at this point.
Easily serializable: GPTQ models support serialization of any number of bits. Loading models from the TheBloke namespace: https://huggingface.co/TheBloke (look for models ending with the -GPTQ suffix) can be used out of the box as long as the required packages are installed. Bitsandbytes supports 8-bit serialization, but does not currently support 4-bit serialization.
AMD support: Integration should work out of the box on AMD GPUs.
What improvements can bitsandbytes have?
Text generation is slower than GPTQ: The bitsandbytes 4-bit model is slower than GPTQ when using generation.
4-bit weights cannot be serialized: Currently, 4-bit models cannot be serialized. This is a frequent request from the community and is on the bitsandbytes maintainer’s roadmap, so we believe it needs to be addressed soon.
What are the potential improvements for autoGPTQ?
Calibration dataset: The need for a calibration dataset may deter some users from utilizing GPTQ. Additionally, model quantization can take several hours (e.g., 4 GPU hours for a 175B scale model according to the paper – Section 2)
Works (currently) only for language models: Currently, the API for quantizing models with automatic GPTQ is designed to support only language models. It should be possible to quantize non-textual (or multimodal) models using the GPTQ algorithm, but the process is not detailed in the original paper or in the auto-gptq repository. If the community is excited about this topic, it may be considered in the future.
Speed benchmark details
We decided to use bitsandbytes and auto-gptq on a variety of hardware to provide extensive benchmarks for both inference and adapter fine-tuning. Inference benchmarks should provide users with the possible speed differences between the different approaches you propose for inference. Also, the Adapter Tweaking Benchmark should give the user a clear idea when deciding which approach to use when tweaking the adapter based on the Bitsandbyte and GPTQ basic models.
Use the following settings:
bitsandbytes: 4-bit quantization with bnb_4bit_compute_dtype=torch.float16. Always use bitsandbytes>=0.41.1 for fast 4-bit kernels. auto-gptq: 4-bit quantization with exllama kernel. Auto-gptq>=0.4.0 is required to use the ex-llama kernel.
Inference speed (previous pass only)
This benchmark measures only the prefill steps corresponding to the forward pass during training. This was run on a single NVIDIA A100-SXM4-80GB GPU with a prompt length of 512. The model used was metal-llama/Llama-2-13b-hf.
If batch size = 1:
Quantization act_order bits group_size Kernel load time (sec) Per-token delay (ms) Throughput (tok/sec) Peak memory (MB) fp16 None None None None 26.0 36.958 27.058 29152.98 gptq False 4 128 exllama 36.2 33.711 29.663 10484.34 Bit and Byte None 4 None None 37.64 52.00 19.23 11018.36
If batch size = 16:
Quantization act_order bits group_size Kernel load time (sec) Per-token delay (ms) Throughput (tok/sec) Peak memory (MB) fp16 None None None None 26.0 69.94 228.76 53986.51 gptq False 4 128 exllama 36.2 95.41 167.68 34777.04 Bit Sand Byte None 4 None None 37.64 113.98 140.38 35532.37
The benchmarks show that bitsandbyes and GPTQ are comparable, with GPTQ slightly faster for large batch sizes. Check this link for more information on these benchmarks.
generate speed
The following benchmark measures the speed of model generation during inference. A benchmark script for better reproducibility can be found here.
use_cache
Let’s test use_cache to better understand the impact of caching hidden state during generation.
The benchmark was run on A100 with a prompt length of 30 and generated exactly 30 tokens. The model used is metal-llama/Llama-2-7b-hf.
If use_cache=True
If use_cache=False
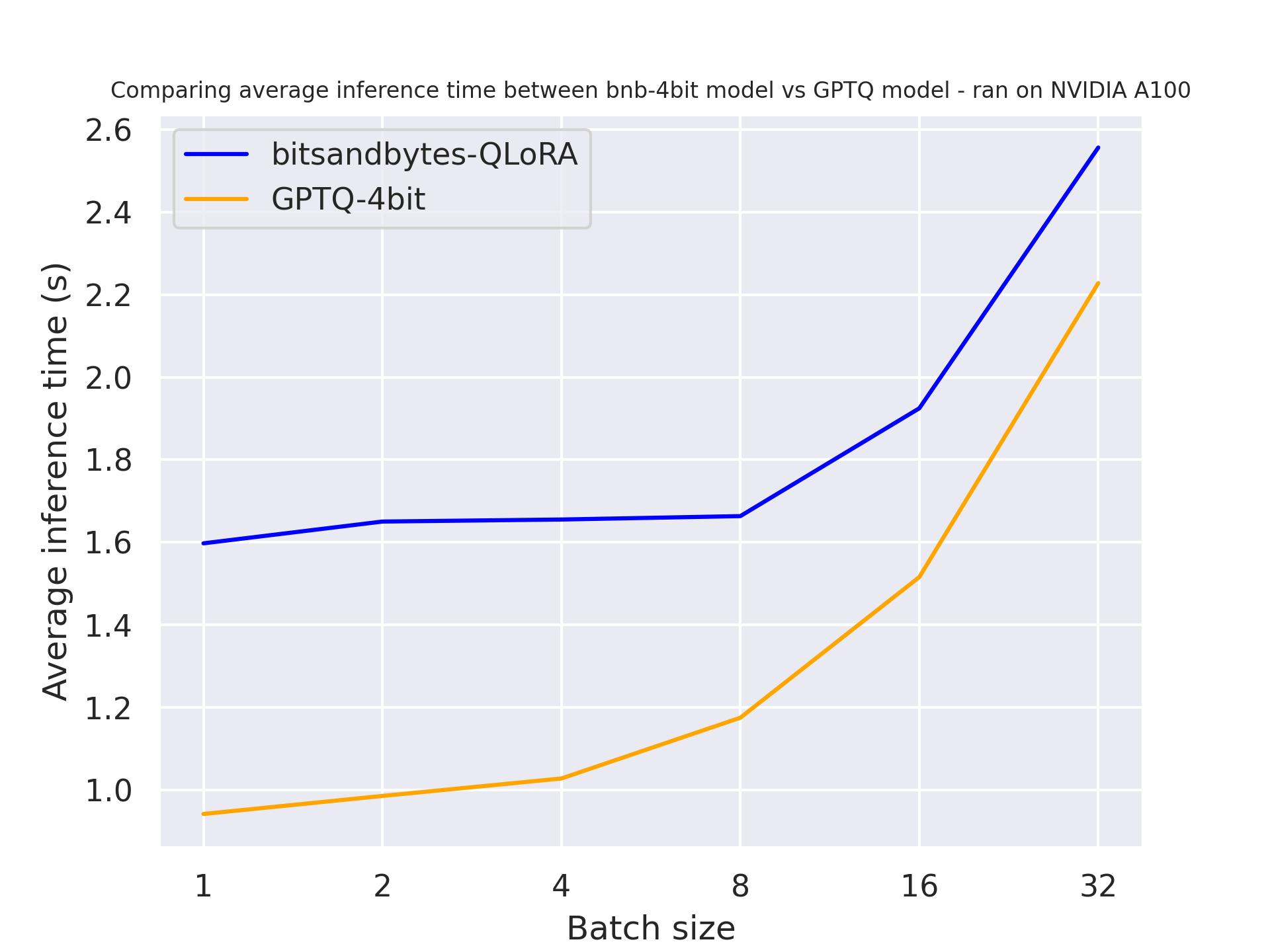
From the two benchmarks, we concluded that, as expected, the attention cache results in faster generation. Additionally, GPTQ is generally faster than BitSandByte. For example, using batch_size=4 and use_cache=True is twice as fast. So let’s use use_cache for our next benchmark. Note that use_cache consumes more memory.
hardware
The next benchmark will try out different hardware to see the impact on the quantization model. We used 30 as the prompt length and generated exactly 30 tokens. The model used is metal-llama/Llama-2-7b-hf.
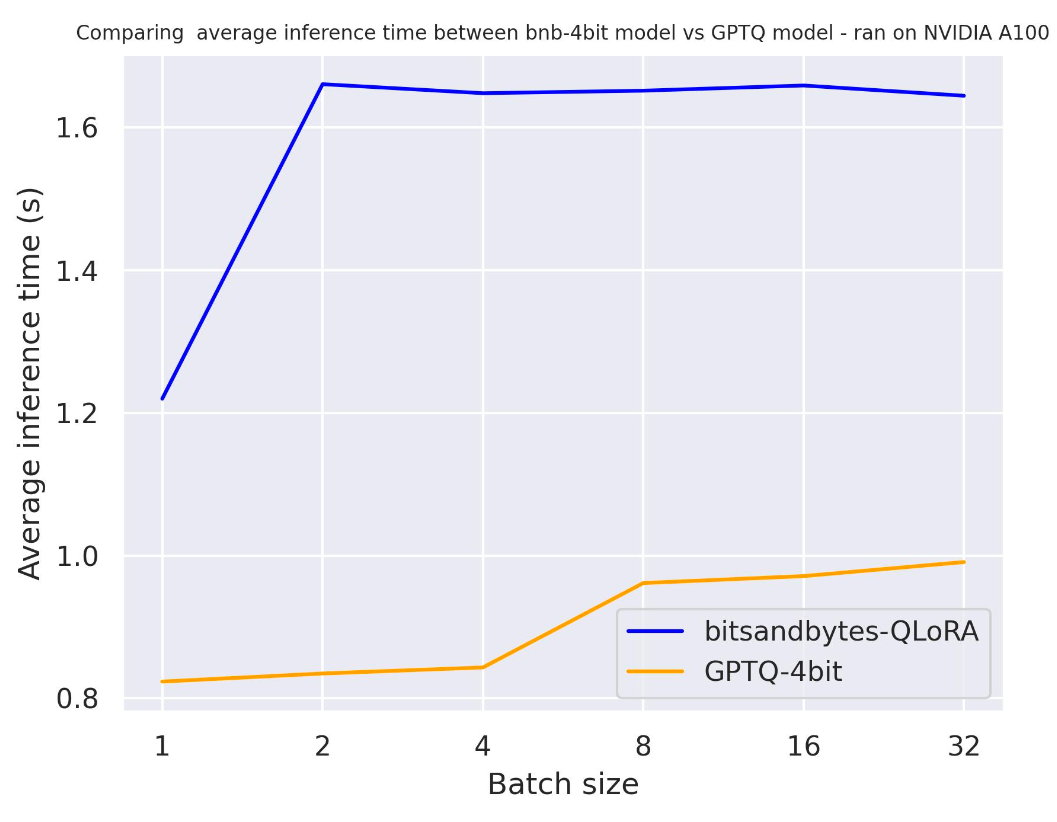
For NVIDIA A100:
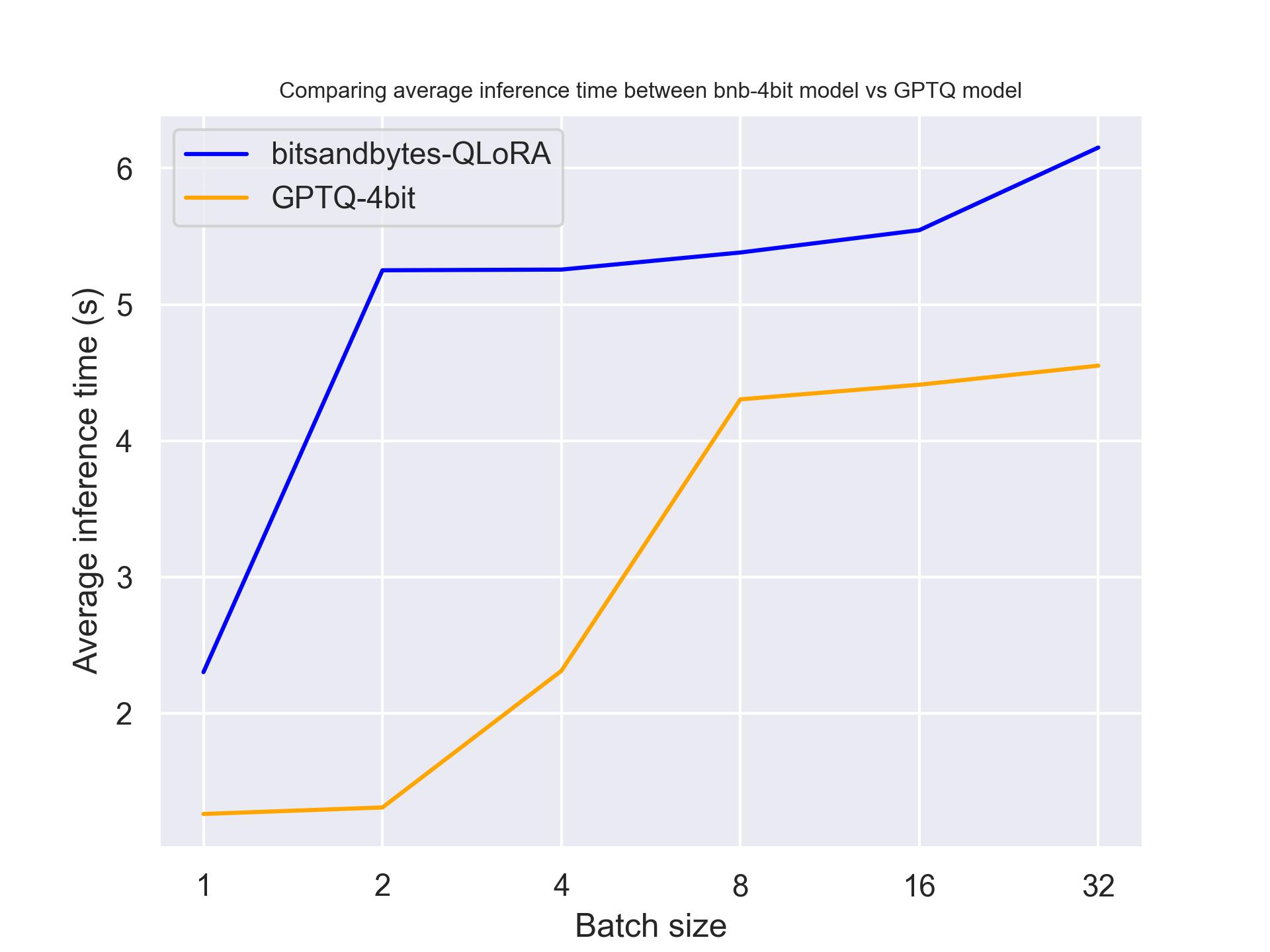
For NVIDIA T4:
With Titan RTX:
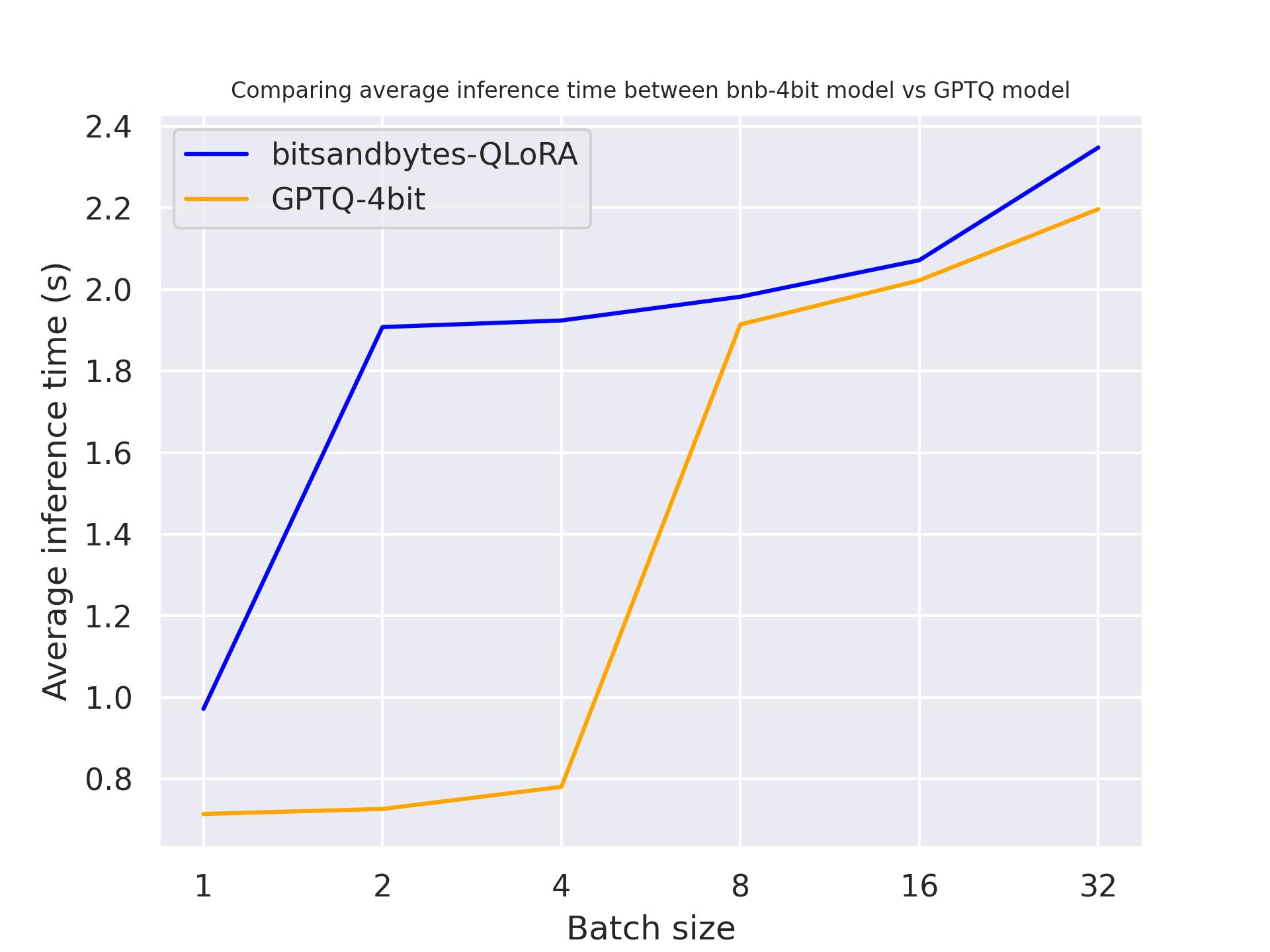
From the above benchmarks, we can conclude that GPTQ is faster than BitSandByte on these three GPUs.
generation length
In the next benchmark, we will try different generation lengths to see the effect on the quantization model. This was run on A100, using a prompt length of 30, and changing the number of tokens generated. The model used is metal-llama/Llama-2-7b-hf.
If 30 tokens are generated:
If 512 tokens are generated:
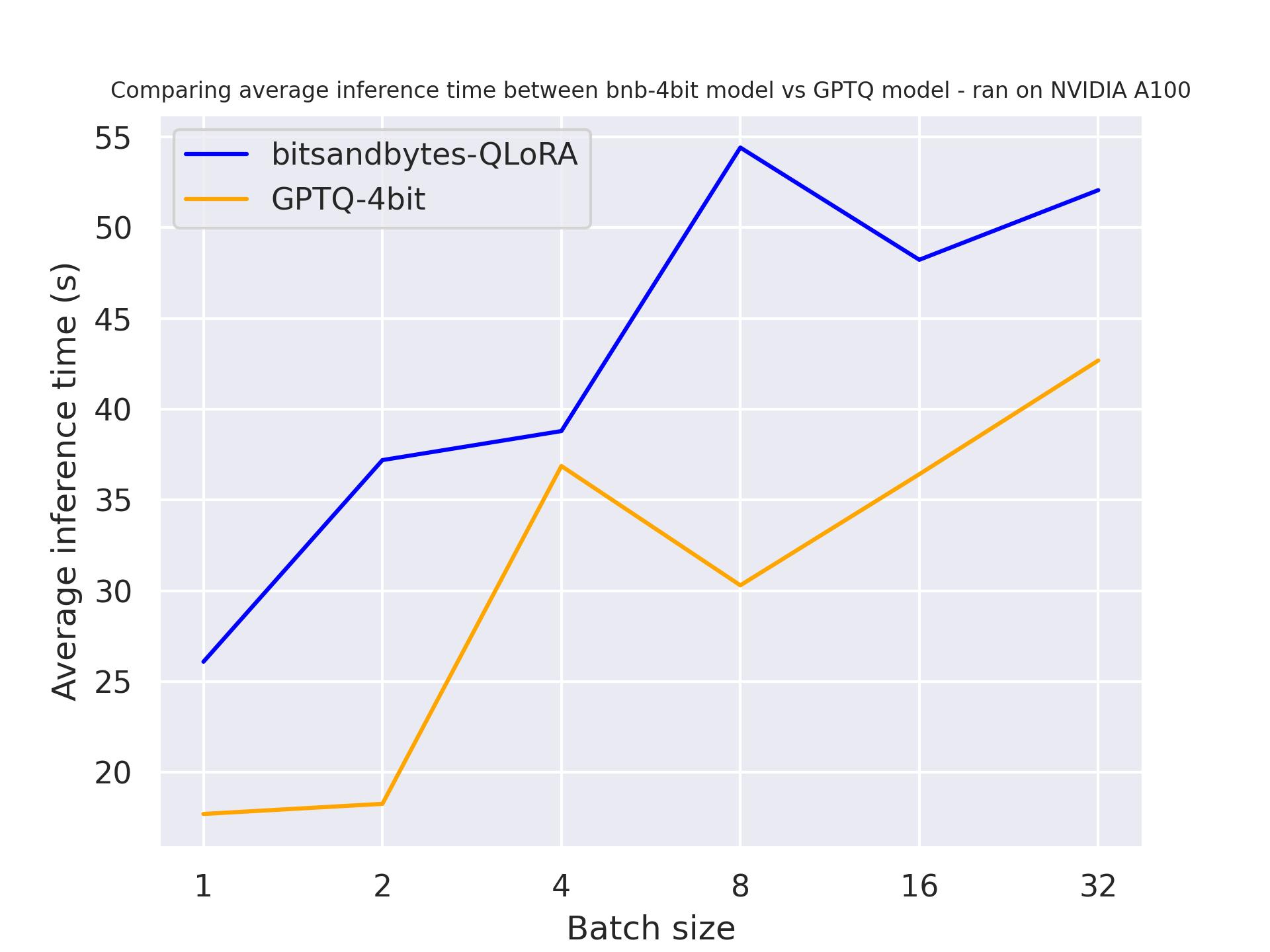
From the above benchmarks, we can conclude that GPTQ is faster than BitSandByte, regardless of the generation length.
Fine adjustment of adapter (forward + backward)
Pure training cannot be performed on a quantized model. However, you can leverage Parameter Efficient Fine-Tuning Method (PEFT) to fine-tune the quantization model and train the adapter on it. The fine-tuning method relies on a recent method called “low-rank adapter” (LoRA). Instead of tweaking the entire model, you can simply tweak these adapters to properly load them within your model. Let’s compare the fine adjustment speed!
The benchmarks were run on an NVIDIA A100 GPU and used the metal-llama/Llama-2-7b-hf model of the hub. Note that for GPTQ models, you need to disable the exllama kernel, as exllama is not supported in fine-tuning.
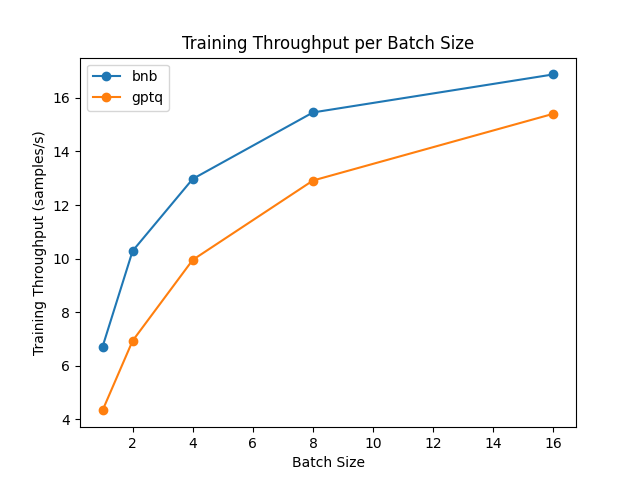
From the results, we can conclude that bitsandbytes is faster than GPTQ when it comes to fine-tuning.
performance degradation
Quantization is great for reducing memory consumption. However, it comes with a performance penalty. Let’s compare performance using Open-LLM leaderboard.
For 7b models:
model_id Average ARC Hellaswag MMLU TruthfulQA metal-llama/llama-2-7b-hf 54.32 53.07 78.59 46.87 38.76 metal-llama/llama-2-7b-hf-bnb-4bit 53.4 53.07 77.74 43.8 38.98 Zabrok/Rama-2-7B-GPTQ 53.23 52.05 77.59 43.99 39.32
For 13b models:
model_id Average ARC Hellaswag MMLU TruthfulQA metal-llama/llama-2-13b-hf 58.66 59.39 82.13 55.74 37.38 TheBloke/Llama-2-13B-GPTQ (Revision = ‘gptq-4bit-128g-actorder_True’) 58.03 59.13 81.48 54.45 37.07 Zabrok/Rama-2-13B-GPTQ 57.56 57.25 81.66 54.81 36.56 Metarama/Rama-2-13b-hf-bnb-4bit 56.9 58.11 80.97 54.34 34.17
From the above results, we can conclude that the larger model has less degradation. More interestingly, the degradation is minimal.
Conclusion and final words
In this blog post, we compared bitsandbite and GPTQ quantization across multiple setups. I found Bitsandbyte to be good for fine-tuning and GPTQ to be good for generation. From this observation, one way to obtain a better coupled model is as follows.
(1) Quantize the base model using bit-sandbiting (zero-shot quantization) (2) Add adapters and fine-tune them (3) Merge the trained adapters on top of the base model or dequantized model. (4) Quantize the merged model using GPTQ and use it for deployment.
We hope this overview makes it easy for everyone to use LLM in their applications and use cases, and we look forward to seeing what you build with it.
Acknowledgment
We would like to thank Ilyas, Clémentine, and Felix for their help in benchmarking.
Finally, I would like to thank Pedro Cuenca for his help in writing this blog post.
