




The rise in generation AI and LLM like CHATGPT has increased the interest and importance of embedding models into a variety of tasks, particularly in searched, perceived generations, such as chatting with data. Embeddings are useful because they are expressed as numeric vector representations, as they represent sentences, images, words, etc. This allows you to map semantically related items and get useful information. This allows you to provide context related to prompts to improve the quality and specificity of production.
Compared to LLM, it embeds a smaller size and faster model for inference. This is very important as you will need to recreate the embedding after modifying the model or improving fine-tuning the model. Furthermore, it is important that the entire search augmentation process be as fast as possible to provide a great user experience.
In this blog post, we show you how to deploy an open source embedded model that hugs the endpoints of facial inference using text-embedded inference, a managed SaaS solution that allows you to easily deploy models. Additionally, we recommend a way to perform large batch requests.
What is embracing face inference endpoint sends an inference embedding model to endpoint as inference endpoint and creates an embedding
Before you begin, update your knowledge of inference endpoints.
1. What hugs the endpoint of facial reasoning?
The endpoint of embracing face reasoning provides an easy and secure way to deploy machine learning models used in production. Inference endpoints allow developers and data scientists to create generated AI applications without managing infrastructure. Simplify the deployment process with a few clicks, including handling large numbers of requests with autofocus, reducing infrastructure costs from scale to zero, and providing high security.
Some of the most important features are:
Easy Deployment: With a few clicks, deploy the model as a production-enabled API, eliminating the need to handle infrastructure or MLOP. Cost-effective: Pay based on endpoint uptime and cost-effective while reducing the infrastructure when endpoints are not in use, benefiting from autoscaling to zero functionality. Enterprise Security: Deploys models with secure offline endpoints that can only be accessed through direct VPC connections backed by SOC2 Type 2 authentication, providing BAA and GDPR data processing agreements for enhanced data security and compliance. LLM Optimization: Optimized for LLMS, allowing high throughput with paged attention and low latency through custom transformer code and flash attention with text-generated inference.
You can start the inference endpoint at https://ui.endpoints.huggingface.co/
2. What is textual embedding inference?
Text Embedded Inference (TEI) is a solution built with the aim of deploying and delivering open source text enmmaging models. TEI is a build for high performance extraction that supports the most popular models. TEI supports all top 10 models of large text embedded benchmark (MTEB) leaderboards, including Flagembedding, Ember, GTE and E5. TEI currently implements the following performance optimization features:
There is no model graph compilation. Get ready for a true serverless! Optimized transformer code token for inference using flash warning, candle, Cublaslt safetenser weight load preparation ready (open telemetry, prometheus metric)
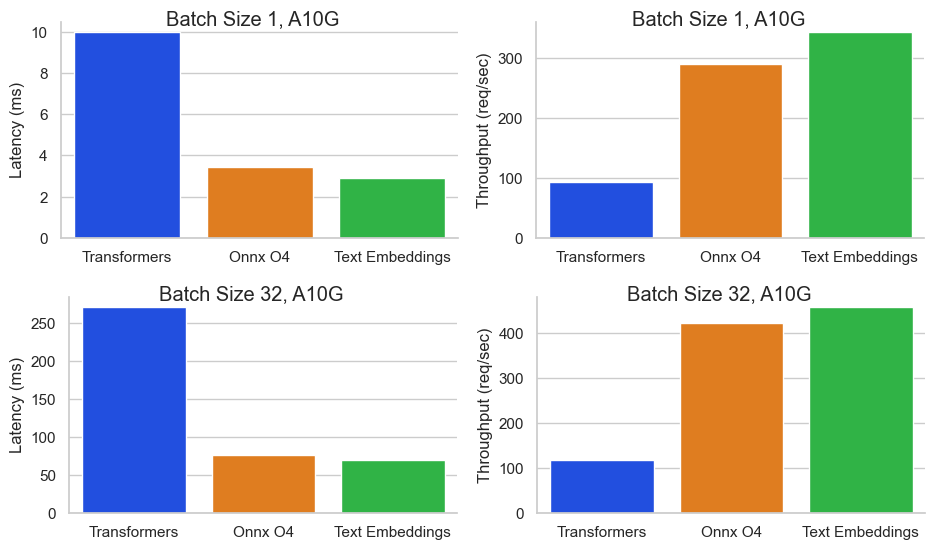
These features allow industry-leading performance in throughput and cost. The Baai/BGE-Base-en-V1.5 benchmarks for NVIDIA A10G inference endpoints with sequence length of 512 tokens and batch sizes of 32 batch sizes yielded a cost of 0.00156 $/1M token or 0.000156 $/1k. This is 64 times cheaper than Openai embedding ($0.0001/1K token).
3. Expand the embedded model as an inference endpoint
To get started, you must be logged in with a user or organizational account with a payment method on the file (you can add it here). You need to access the inference endpoint at https://ui.endpoints.huggingface.co.
Next, click on “New Endpoint.” Select a repository, cloud, and region, adjust the instance and security settings, and deploy for Baai/BGE-Base-En-V1.5.
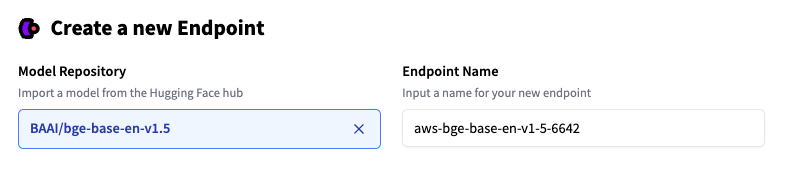
The inference endpoint suggests an instance type based on model size. This is large enough to run the model. Here’s the Intel Ice Lake 2 VCPU. To get the performance of the benchmark, change the instance to 1x Nvidia A10g by running it.
Note: If you are unable to select an instance type, you must contact us to request an instance quota.

You can then click Create Endpoint to expand the model. After 1-3 minutes, the endpoint should be online and ready to serve requests.
4. Send a request to the endpoint and create an embed
The endpoint overview provides access to the inference widget. This can be used to manually submit requests. This allows you to quickly test endpoints with different inputs and share them with team members.
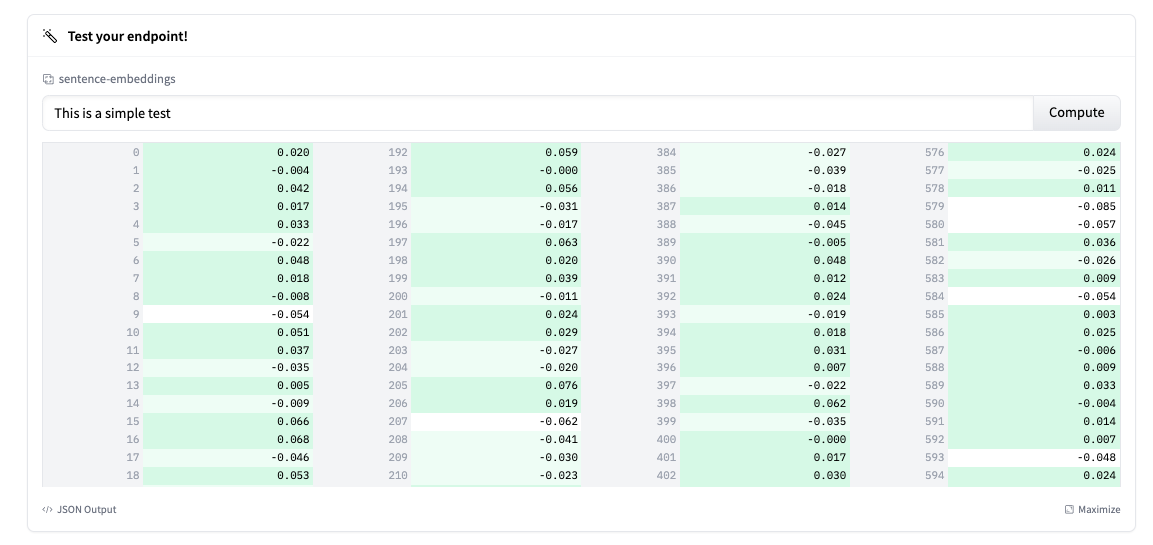
Note: TEI is currently not automatically truncating inputs. Truncate: You can enable this by setting true.
In addition to widgets, the overview provides code snippets for Curl, Python and JavaScript. This can be used to send requests to the model. The code snippet shows how to send a single request, but TEI also supports batch requests, allowing multiple documents to be sent to increase endpoint usage. Below is an example of how to send a batch request with a truncation set set to true:
Import Request API_URL = “https://l2skjfwp9punv393.us-east-1.aws.endpoints.huggingface.cloud”
Header= {
“Approval”: “Your Token Bearer”,
“Content Type”: “Application/json”
}
def Query(payload): response = requests.post(api_url, headers = headers, json = payload)
return Response.json() output = query({
“input”🙁“Sentence 1”, “Sentence 2”, “Sentence 3”),,
“Truncate”: truth
})
Conclusion
The TEI embraces the endpoint of facial inference, allowing for the ferocious, burning, cost-effective deployment of cutting-edge embedded models. With industry-leading throughput of over 450 requests per second and low cost of $0.00000156/1K tokens, the inference endpoint offers 64 times more cost savings than OpenAI embedding.
For developers and businesses who leverage text embedding to enable semantic search, chatbots, recommendations and more, hugging the facial inference endpoint eliminates infrastructure overlasting and provides high throughput at the lowest cost to streamline processes from research to production.
Thank you for reading! If you have any questions, please feel free to contact us via Twitter or LinkedIn.
