


Instruction tuning is a tweaking approach that gives the large-scale language model (LLM) the ability to follow written instructions by nature and humans. However, for programming tasks, most models are tuned with either human-generated instructions (very expensive) or instructions generated by huge, own LLMS (sometimes not allowed). Introducing StarCoder2-15B-Instruct-V0.1. This is the first fully self-adjusted code LLM trained in a fully acceptable transparent pipeline. Our open source pipeline uses StarCoder2-15B to generate thousands of instruction response pairs. This is used to fine-tune the Starcoder-15B itself without human annihilation or distillation data from the huge and unique LLMS.
StarCoder2-15B-Instruct has achieved a 72.6 human score and exceeds the 72.0 score of the Cordrama-70B-Instruct! Further evaluations in LiveCodebench show that the self-aligned model is superior to the same model trained with data distilled from GPT-4, meaning that LLM can learn more effectively from data within its own distribution than from the shift distribution from the teacher LLM.
method

The data generation pipeline consists of three main steps:
Extract high quality, diverse seed features from Stack V1, a huge corpus of permitted source code. Create a variety of realistic code instructions that incorporate the various code concepts that exist in seed functions (e.g., data descent, list concatenation, recursion). For each instruction, we generate a high-quality response through self-verification with execution guide.
The next section examines each of these aspects in detail.
Collecting seed code snippets
To completely unlock functions that follow the instructions of the code model, one must be exposed to a diverse set of instructions, including a wide range of programming principles and practices. Motivated by OSS-Instruct, this diversity is further promoted, especially by mining code concepts from open source code snippets, a well-formed seeded Python feature from stack V1.
In the seed dataset, we carefully extract all Python functions in Stack V1’s docustrings, use Autoimport to infer the required dependencies, and apply the following filtering rules to all functions:
Type Check: Apply Pyright Heuristic Type-Checker to remove all features that generate static errors and indicate incorrect items. Decontamination: Detect and delete all benchmark items to evaluate. Use exact string matches in both the solution and the prompt. Docstring Quality Filtering: Use StarCoder2-15B as a judge to remove insufficient documentation features. You should prompt the base model for seven fewer shot examples and respond with “yes” or “no” to hold the item. Near approximation: We utilize minhash and region-sensitive hash with similar thresholds for jackards of 0.5 to filter overlapping seed functions in the dataset. This is the same process that applies to Starcoder training data.
This filtering pipeline results in a dataset of 250K Python functions filtered from a 5M function using docustrings. This process is very inspired by the data collection pipeline used by Multipl-T.
Self-enormous instructions
After collecting seed functions, they generate a variety of instructions using their own instructions. In particular, the base StarCoder2-15B from a specific seed code snippet employs in-context learning to enable self-generated instructions. This process utilizes 16 carefully designed several shot examples, each formatted as (snippets, concepts, instructions). The instruction generation procedure is divided into two steps.
Concept Extraction: For each seed function, StarCoder2-15B is asked to create a list of code concepts that exist within the function. The concept of code refers to basic principles and techniques used in programming, such as pattern matching and data type conversion. This is important for developers to master. Instruction Generation: StarCoder2-15B is asked to self-generate coding tasks that incorporate the identified code concepts.
Ultimately, this process generates 238k instructions.
Self-verification of response
Given the instructions generated from self-extensive instructions, the next step is to match each instruction with a high quality response. Previous practices generally rely on distillation responses from stronger teacher models such as GPT-4, which hopefully can exhibit higher quality. However, distilling your own models leads to non-human licensing and more powerful teacher models are not always available. More importantly, teacher models may also be incorrect, and the distribution gap between teachers and students may be harmful.
We propose to self-regulate the StarCoder2-15B by explicitly instructing the model to generate self-validation tests after generating responses interleaved with natural language. This process is similar to how developers test implementations of their code. Specifically, for each instruction, StarCoder2-15B generates 10 samples of format (NL responses, tests) and excludes those forged by test execution in a sandbox environment. Next, we randomly select one pass response for each instruction to the final SFT dataset. In total, we generated a 2.4m (10 x 238k) response for a 238K instruction with temperature 0.7, with 500K passing the execution test. After deduplication, there is a 50K instruction left, each paired with a random pass response, which will ultimately be used as an SFT data set.
evaluation
On the popular and rigorous EvalPlus benchmark, StarCoder2-15B-Instruct stands out as the top-performing permissive LLM at its scale, outperforming the much larger Grok-1 Command-R+, DBRX, while closely matching Snowflake Arctic 480B and Mixtral-8x22B-Instruct.To our knowledge, StarCoder2-15B-Instruct is the first code LLM where a completely transparent and forgiving pipeline reaches a human score of 70+. This is dramatically better than the previous state-of-the-art tolerance code LLM with a transparent pipeline.
Compared to a powerful LLMS with a restrictive license, the StarCoder2-15B-Instruct is competitive, larger than Gemini Pro, and rivals the Coderama-70B-Instruct. Additionally, StarCoder2-15B-Instruct, trained purely with self-generated data, closely rivals the Finetunes StarCoder2-15B with GPT-3.5/4 distillation data.
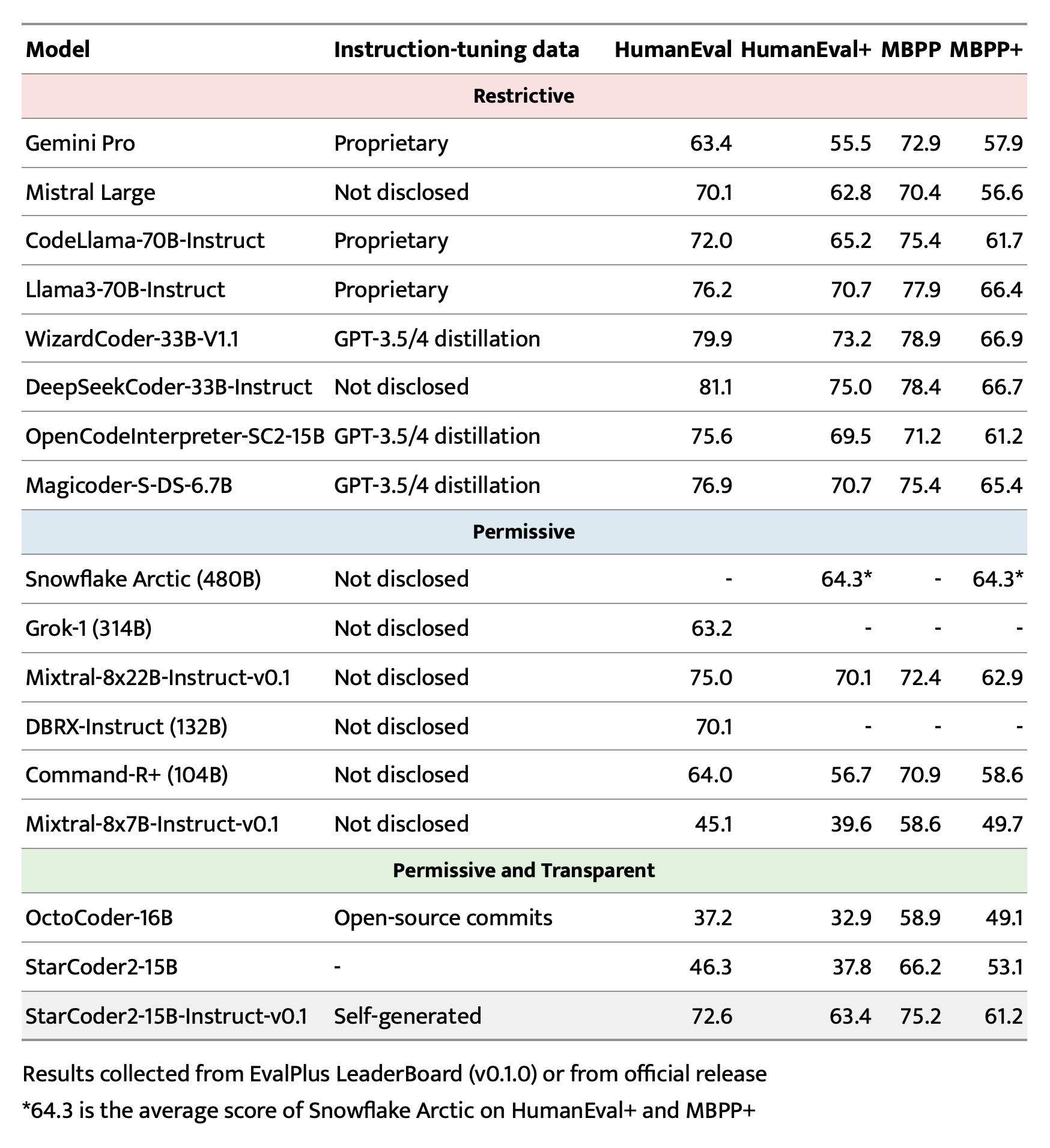
In addition to the evaluation, we also evaluated fresh coding issues created since 2023-09-01 and cutting-edge open source models with similar or smaller sizes of LiveCodebench, including the DS-1000 targeting data science programs. In LiveCodeBench, StarCoder2-15B-Instruct achieves the best results and consistently outperforms among models that evaluate OpenCodeInterPreter-SC2-15B, which distills GPT-4 data. With the DS-1000, despite being trained on very limited data science issues, the StarCoder2-15B-Instruct remains competitive.
Conclusion
StarCoder2-15B-Instruct-V0.1 is the first to introduce you to the creation of powerful instruction tuning code models without relying on powerful teacher models such as GPT-4. This model shows that self-adjustment in which the model learns using its own generated content is also effective in code. It is completely transparent, allows for distillation and sets it apart from other greater tolerance but non-transparent models, such as Snowflake-Ark, GROK-1, Mixtral-8X22B, DBRX, and CommandR+. We’ve completely opened sourced the dataset and the entire pipeline, including data curation and training. I hope this ingenious work will inspire future research and development in this field.
resource
Quote
@article {wei2024 selfcodealign, title = {selfcodealign: code for code for code generation}, author = {yuxiang wei and jiawei liu and yifeng ding and naman jain and zachary mueller and harm de de von werra and arjunguha and year = {2024}, journal = {arxiv preprint arxiv: 2410.24198}}}}
