


When you think about building a model, whether it’s a large-scale language model (LLM) or a small-scale language model (SLM), the first thing you need is data. Although vast amounts of open data are available, it is rarely provided in the precise format needed to train and tune models. In practice, we often face scenarios where raw data alone is not enough. You need data that is more structured, domain-specific, complex, or tailored to the task at hand. Let’s look at some common situations.
Missing complex scenarios
We start with a simple dataset, but the model fails on advanced inference tasks. How can we generate more complex datasets to enhance performance?
From knowledge base to Q&A
We already have a knowledge base, but it’s not in a Q&A format. How can I turn this into a usable question answer dataset?
From SFT to DPO
A supervised fine-tuning (SFT) dataset has been prepared. But now we want to tune the model using Direct Preference Optimization (DPO). How can we generate the pairs we like?
depth of question
There is a Q&A dataset, but the questions are shallow. How can you create probing, multi-turn, or inference-oriented questions?
Domain-specific intermediate training
I have a huge corpus, but I need to filter and curate the data during training on a specific domain.
Convert PDFs and images to documents
Since your data is stored in PDF or images, you need to convert it into a structured document to build your Q&A system.
improve reasoning ability
We already have an inference dataset, but we want to push the model towards better “thought tokens” to solve the problem step by step.
quality filtering
Not all data is good data. How can you automatically filter out low-quality samples and keep only high-value samples?
Contexts from small to large
Although the dataset contains small chunks of context, we would like to build a larger context dataset that is optimized for the RAG (Retrieval Augmentation Generation) pipeline.
Conversion between languages
I have a German dataset that I need to translate, adapt, and reuse into an English Q&A system. And the list goes on. When using modern AI models, your data building needs are never-ending.
Introducing SyGra: One framework for all your data challenges
This is where SyGra comes into play. SyGra is a low-code/no-code framework designed to simplify the creation, transformation, and alignment of LLM and SLM datasets. Instead of writing complex scripts and pipelines, SyGra takes care of the heavy lifting so you can focus on faster engineering.
Key features of SyGra:
✅ Python Libraries + Frameworks: Easily integrate into your existing ML workflows using SyGra libraries. ✅ Supports multiple inference backends: Works seamlessly with vLLM, Hugging Face TGI, Triton, Ollama, and more. ✅ Low-code/no-code: Build complex datasets without significant engineering effort. ✅ Flexible data generation: From Q&A to DPO, inference to multilingualism, SyGra adapts to your use case.
Why SyGra matters
Data is the foundation of AI. Data quality, diversity, and structure are often more important than model architecture adjustments. By enabling the creation of flexible, scalable datasets, SyGra helps teams:
Accelerate model tuning (SFT, DPO, RAG pipelines). Save engineering time with plug-and-play workflows. Improve model robustness across complex domain-specific tasks. Reduce manual dataset curation efforts.
Note: An example implementation can be found at https://github.com/ServiceNow/SyGra/blob/main/docs/tutorials/image_to_qna_tutorial.md.
SyGra architecture
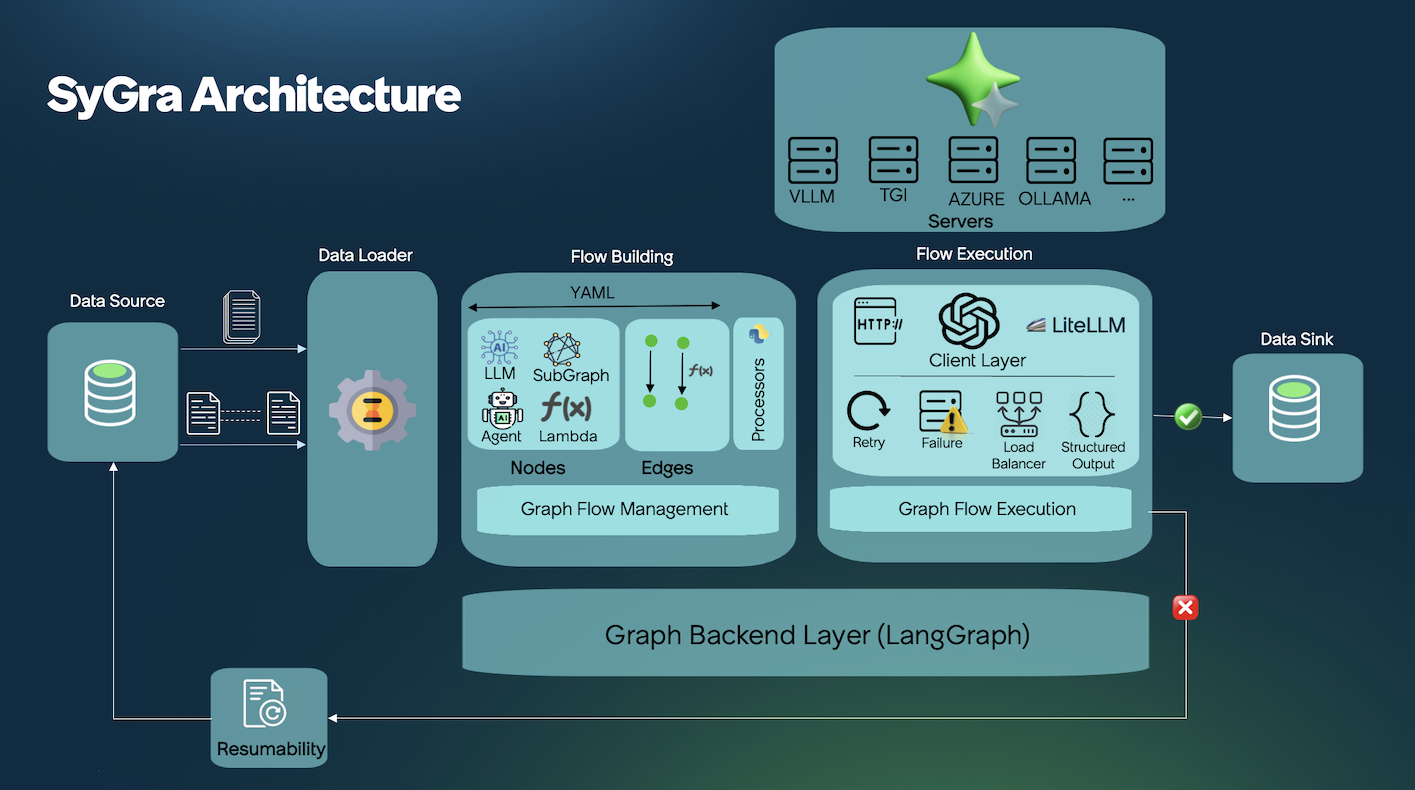
Some task examples https://github.com/ServiceNow/SyGra/tree/main/tasks/examples
final thoughts
The journey of building and improving datasets never ends. Each use case brings new challenges, from translation and knowledge base transformation to inference enhancement and domain filtering. With SyGra, you don’t have to reinvent the wheel every time. Instead, you get an integrated framework that lets you generate, filter, and refine data for your models, so you can focus on what really matters: building smarter AI systems.
References
Paper link: https://arxiv.org/abs/2508.15432 Document: https://servicenow.github.io/SyGra/ Git repository: https://github.com/ServiceNow/SyGra
