


Supplementary note
After consulting with the author of the IPO paper, I discovered that the implementation of IPO in TRL was incorrect. In particular, losses to logarithmic liability for completion should be averaged instead of summing them. I added a fix to this PR and rerun the experiment. The results are currently in line with the paper, with IPOs comparable to DPOs and performing better than KTOs in paired configuration settings. I updated my post to reflect these new results.
tl; dr
We evaluate three promising ways to align language models without reinforcement learning (or preference adjustment) with many models and hyperparameter settings. In particular, we train using a variety of hyperparameters to evaluate:
introduction
In this post, we perform an empirical assessment of three promising LLM alignment algorithms: direct preference optimization (DPO), ID-preferred optimization (IPO), and Kahneman-Tversky Optimization (KTO). We conducted the experiments with two high quality 7B LLMS, despite having monitored fine-tuning steps but no prioritization alignment. Although some algorithms clearly outperform others, we can see that there are important hyperparameters that need to be adjusted to achieve the best results.
Alignment without reinforcement learning
Direct Preference Optimization (DPO) has emerged as a promising alternative to large-scale language models (LLMs) to suit human or AI preferences. Unlike traditional alignment methods based on reinforcement learning, DPO re-occurs the alignment formulation as a simple loss function that can be optimized directly on the dataset of the configuration {(x, yw, yl)} \{(x, y_w, y_l)\} where xx It’s a prompt YW, YLY_W, Y_L It is a favorable response and distribution.
Sample of a priority tuning dataset.
This makes DPO practical and has been successfully applied to train models such as Zephyr and Intel’s NeuralChat.
The success of DPO has led researchers to develop new loss functions that generalize the methods in two main directions.
Robustness: One drawback of DPO is its tendency to rapidly over-adopt it in preferred datasets. To avoid this, Google Deepmind researchers have introduced ID preference optimization (IPO). This adds normalization terminology to DPO losses, allowing the model to be trained without the need for tricks such as early arrest. Distribute pair configuration data perfectly: Like most alignment methods, DPO requires a dataset of pair configuration {(x, yw, yl)} \{(x, y_w, y_l)\} annotators label which responses are superior according to a set of criteria such as usefulness and harm. In reality, creating these datasets is a time-consuming and expensive effort. Contextualai recently proposed an interesting alternative called Kahneman-Tversky Optimization (KTO). This fully defines the loss function in terms of individual examples labeled “good” or “bad” (for example, 👍 or 👎 icons seen in the chat UI). These labels are actually much easier to get, and KTO is a promising way to continuously update chat models running in production environments.
At the same time, these various methods come with hyperparameters. The most important method is β\Beta controls the amount of weighting the preference of the reference model. These alternatives have made them available in practitioners’ arsenals through libraries such as 🤗TRL. The natural question is what among these methods and hyperparameters would be the one that generates the best chat model?
This post aims to answer this question by performing an empirical analysis of three methods. Sweep key hyperparameters like this β\Beta Perform the training procedure and evaluate the performance of the resulting model through the MT bench. This is a general benchmark for measuring chat model functionality.
Please provide open source code to reproduce these results.
Let’s get started!
link
Important links related to the analysis are as follows:
Experiment setup
There are two main components that need to be considered when performing alignment experiments. The model and alignment dataset selected for optimization. To obtain more independent data points, we examined two models of OpenHermes-2.5-Mistral-7B and Zephyr-7B-Beta-Sft, and two alignment datasets Intel ORCA_DPO_PAIRS and UltraFeedback binary datasets.
In the first experiment, we used OpenHermes-2.5-Mistral-7B. This is because it is one of the best 7B parameter chat models that are not subject to alignment techniques. I then used Intel’s ORCA_DPO_PAIRS dataset. It consists of a 13K prompt where the selected response is generated by GPT-4 and the undesired response is generated by Llama-chat 13b. This is the dataset behind NeuralChat and NeuralHermes-2.5-Mistral-7B. KTO does not require pairwise preferences in itself, so it simply treats the level of the Llama-chat 13B as “bad” with the GPT-4 response as a “good” label. Although the response of GPT-4 may be preferred over Llama-chat 13b, we consider this to represent a few examples, although Llama-chat-13b may produce a better response.
In the second experiment, we performed a priority alignment of the Zephyr-7B-beta-SFT model. This includes a 66K prompt with a pair of selected and rejected responses. This dataset was used to train the original Zephyr model. This was the best in the class 7B model at the time with numerous automatic benchmarks and human ratings.
Experimental structure
The Alignment Handbook provides a simple way to organize a single experiment. These parameters are used to configure the run_dpo.py script.
model_name_or_path: Teknium/OpenHermes-2.5-Mistral-7B
torch_dtype: null
dataset_mixer:
Huggingfaceh4/orca_dpo_pairs: 1.0
dataset_splits:
– train_prefs
– test_prefs
preprocessing_num_workers: 12
BF16: truth
beta: 0.01
loss_type: sigmoid
do_eval: truth
do_train: truth
evaluation_strategy: Steps
eval_steps: 100
gradient_accumulation_steps: 2
gradient_checkpointing: truth
gradient_checkpointing_kwargs:
use_reintrant: error
hub_model_id: huggingfaceh4/openhermes-2.5-mistral-7b-dpo
hub_model_revision: v1.0
Learning_rate: 5.0E-7
logging_steps: 10
lr_scheduler_type: cosine
max_prompt_length: 512
num_train_epochs: 1
Best: adamw_torch
output_dir: Data/OpenHermes-2.5-Mistral-7B-DPO-V1.0
per_device_train_batch_size: 8
per_device_eval_batch_size: 8
push_to_hub_revision: truth
save_strategy: “Step”
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1
I created a similar base configuration file for Zephyr experiments.
The chat template was automatically inferred from the Base Chat model, and OpenHermes-2.5 was used using CHATML format and Zephyr using the H4 chat template. Alternatively, if you use your own chat format, the 🤗Tonizer Library now enables user-defined chat templates using jinja-style strings.
“Message %}\n{%Message(‘role’)==’user’%}\n{{‘\n’ + message(‘content’) + eos_token}}\n{%elif message(‘role’)==’system’%}\n{‘\n’ + message(‘role’)==’assistant’%}\n{{‘\n’ + message(‘content’) + eos_token}}\n{%endif%}\n{%loop.last and add_generation_prompt%}\n{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{
Format the conversation like this:
Hyperparameter sweep
I trained the DPO, IPO, and KTO methods via dpotrainer in loss_type argument TRL, and got the beta version from 0.01, 0.1, 0.2, …, 0.9. We included 0.01 as we observed that some alignment algorithms were particularly sensitive to this parameter. All experiments were trained for one era. All other hyperparameters are kept the same during each run, including random seeds.
I then launched a scan on the face cluster of hugs using the base configuration above. #gpurich
configs =(“Zephyr” “OpenHermes”) loss_types =(“sigmoid” “kto_pair” “IPO”)Beta = (“0.01” “0.1” “0.2” “0.3” “0.4” “0.5” “0.6” “0.7” “0.8” “0.9”))
for config in “${configs(@)}“; do
for loss_type in “${loss_types(@)}“; do
for beta in “${betas(@)}“; do
job_name =“$config_${loss_type}_beta_${beta}“
model_revision =“${loss_type}–${beta}“
sbatch -job-name =${job_name} Recipes/launch.slurm dpo pref_align_scan config_$ config deepspeed_zero3 \\
” – Betta=${beta} -loss_type =${loss_type} -output_dir = data/$ config-7b-align-scan-${loss_type}-beta-${beta} -hub_model_revision =${model_revision}“
end
end
end
result
All models were evaluated using GPT-4 using the MT Bench, a multi-turn benchmark that judges the performance of the model in eight different categories: Writing, Roleplay, Inference, Mathematics, Coding, Extraction, STEM, and the Humanities. Although incomplete, the MT bench is a good way to evaluate LLM in conversation.
Zephyr-7b-beta-sft
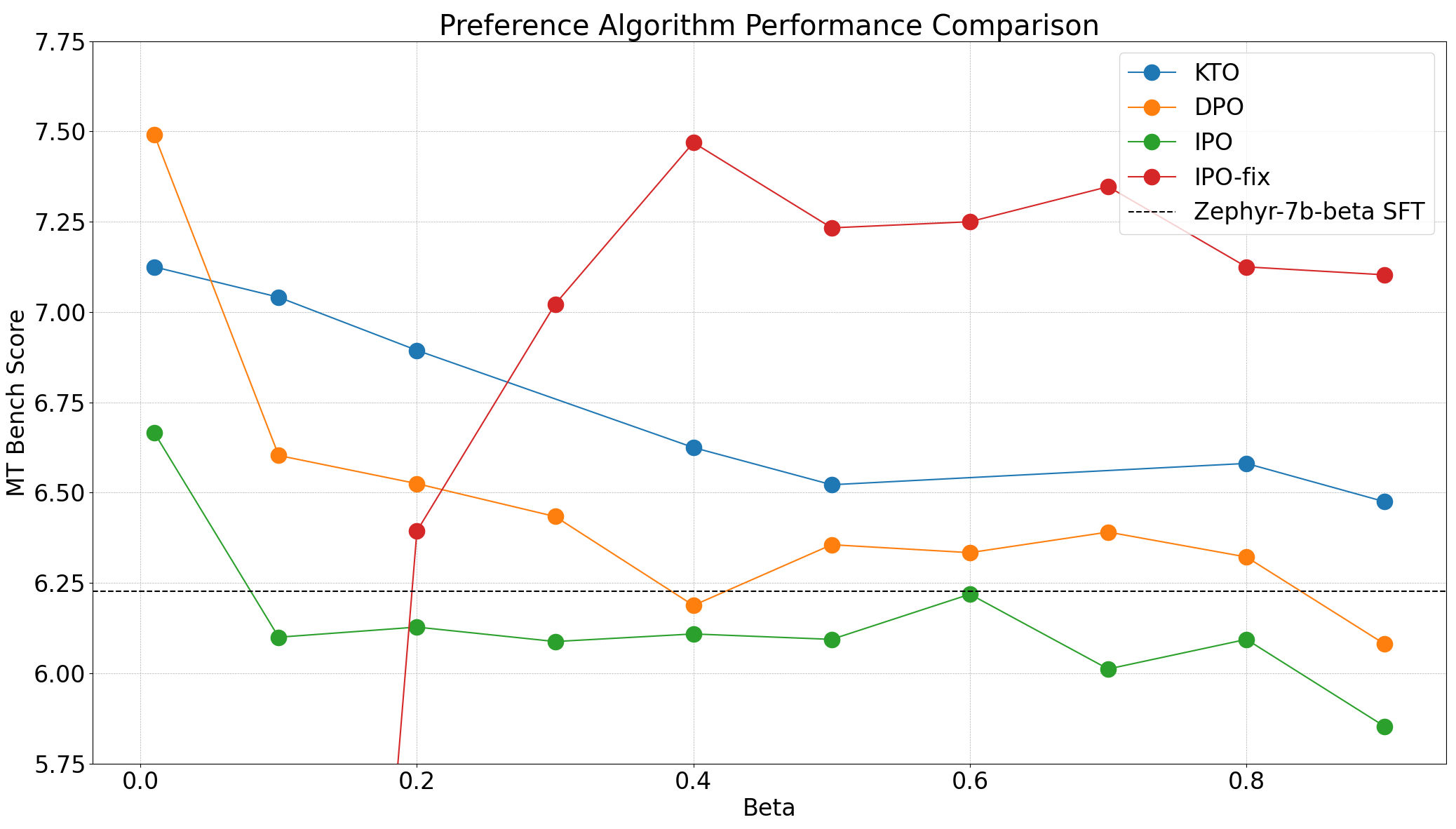
MT bench scores for Zephyr models for different β\Beta .
In the Zephyr model, we observed that the best performance was achieved at the lowest β\Beta Value, 0.01. This is consistent across all three algorithms tested. An interesting follow-up on community experiments is fine grain scans ranging from 0.0-0.2. DPO can achieve the best MT bench score, but we found that KTO (with pair) achieves better results in all settings except one. The IPO has a stronger theoretical guarantee, but appears to be worse than the base model in all but one settings.
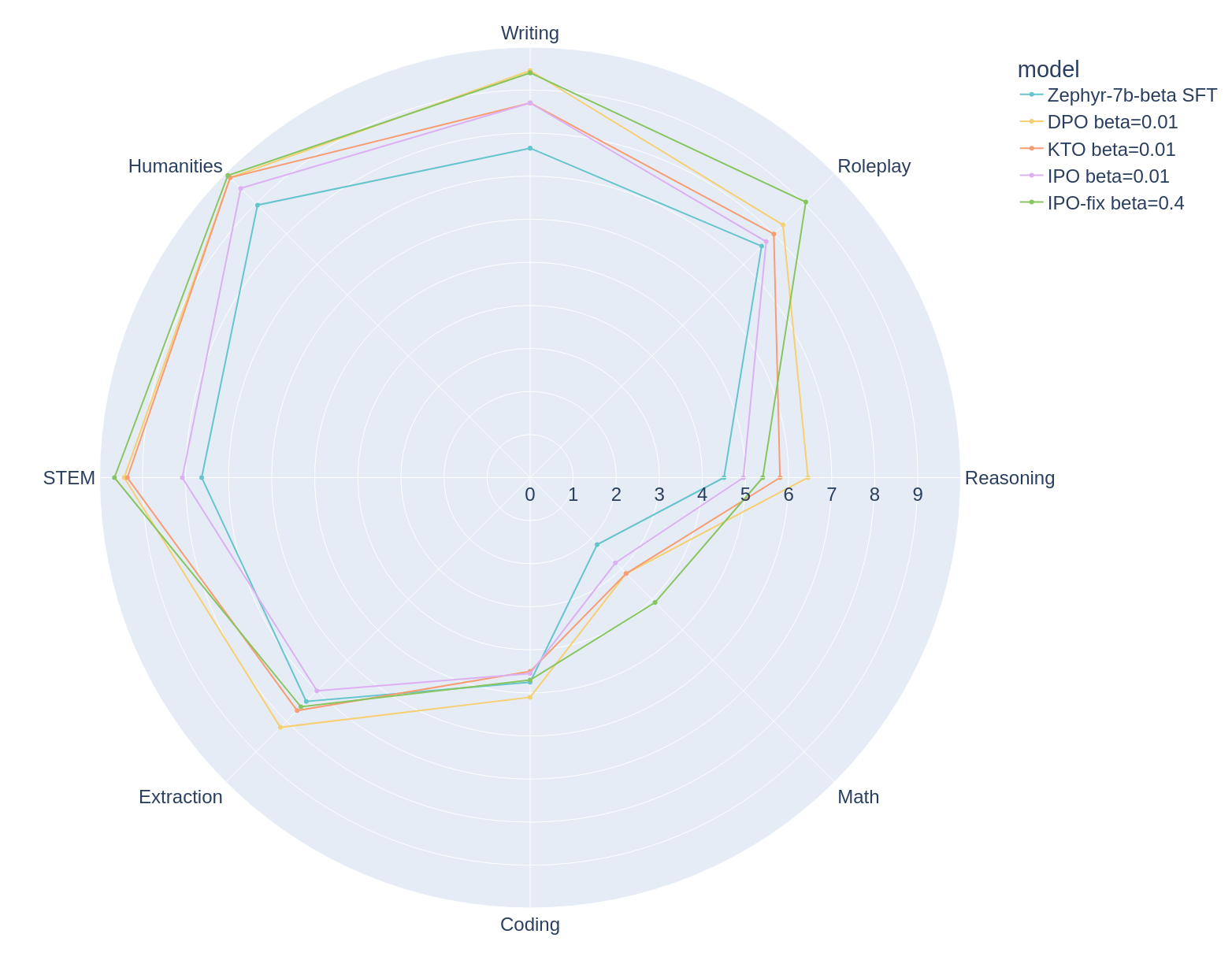
Decomposition of the best Zephyr model for each algorithm across the MT bench category.
The best results for each algorithm can be decomposed across categories that MT Bench evaluates and identifies the advantages and disadvantages of these models. There is still a wide area to improve on the inference, coding and mathematics axis.
OpenHermes-7B-2.5
The observations on each algorithm remain the same in OpenHermes, but that is DPO>KTO>IPO, or sweet spot β\Beta It varies greatly from algorithm to algorithm. With the best choice of β\Beta For DPOs, the KTO and IPO are 0.6, 0.3, and 0.01, respectively.
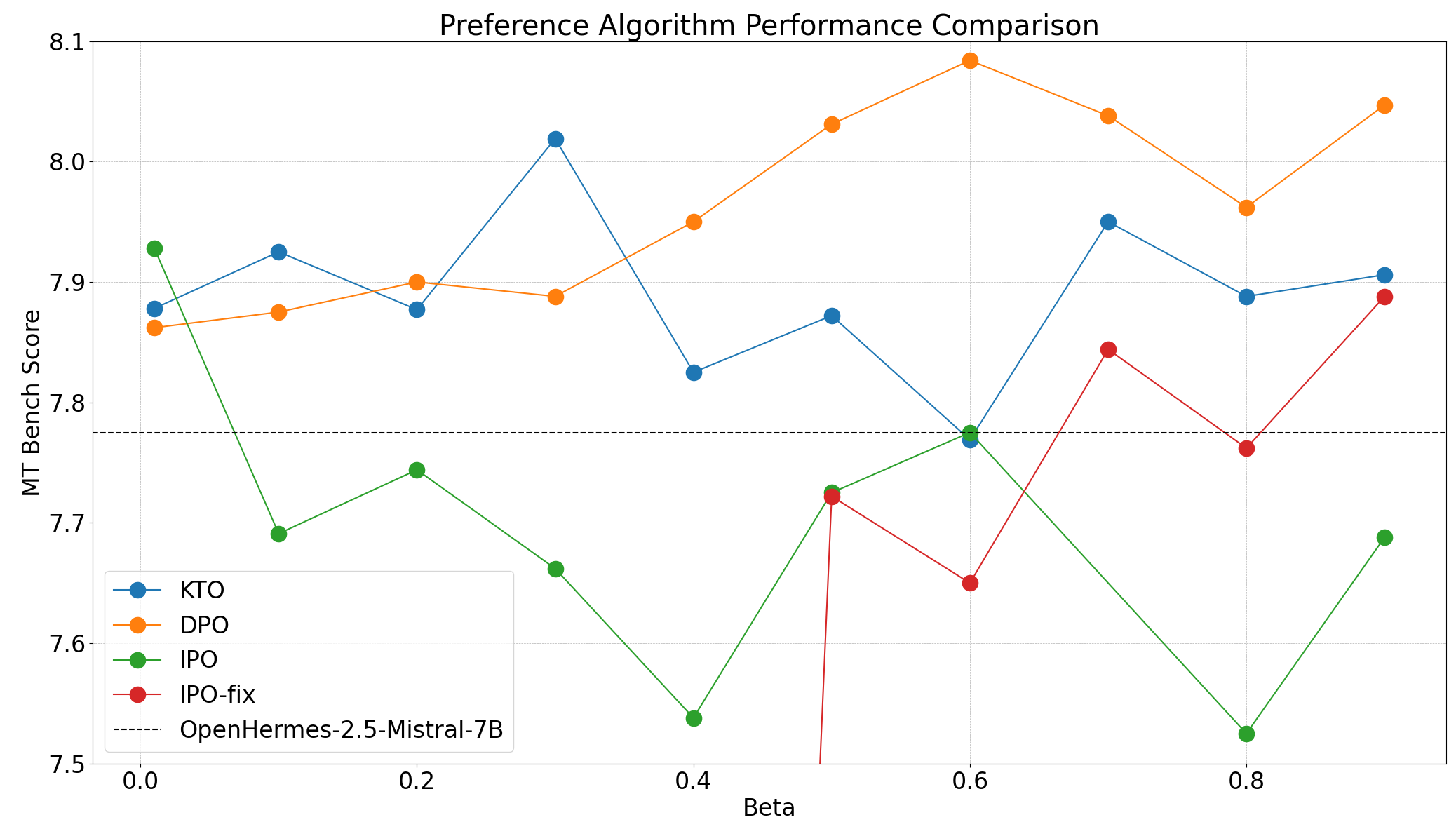
Because the MT bench scores of OpenHermes models are different β\Beta .
The OpenHermes-7B-2.5 is clearly a more powerful base model, with only 0.3 improvement in MT bench score after priority alignment.
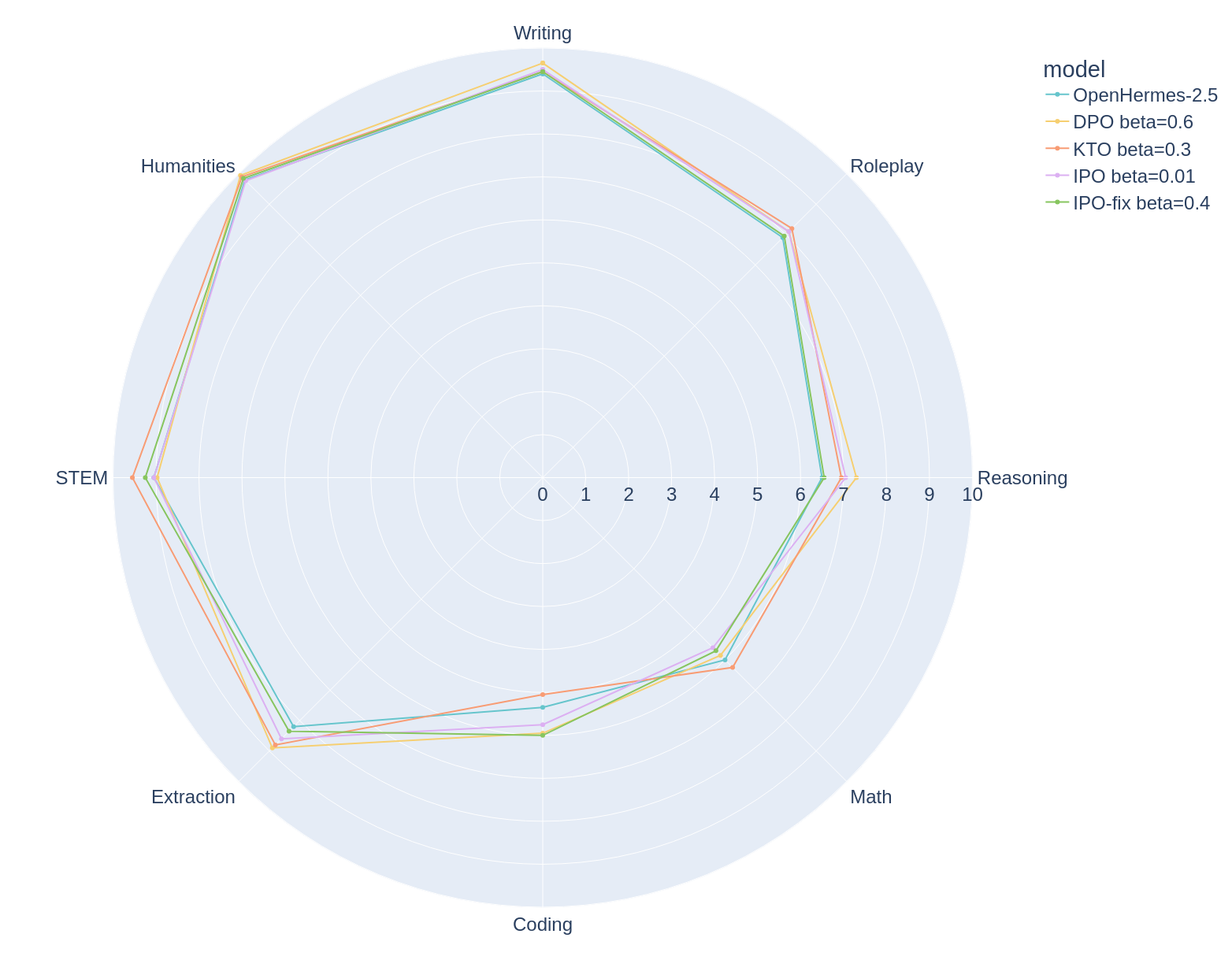
Decomposition of the optimal OpenHermes model for each algorithm across the MT bench category.
Summary and insights
In this post, I highlighted the importance of selecting the appropriate hyperparameters when performing a priority alignment. We demonstrate empirically that DPO and IPO can achieve comparable results, and can outperform KTO in paired settings.
All code and configuration files that replicate these results are now available in the Alignment Handbook. This collection features the best performance models and datasets.
What’s next?
Implement the new Preference Alignment Algorithms in the TRL and continue to evaluate its performance. For the time being, at least for the time being, DPO appears to be the most robust and performant LLM alignment algorithm. KTO remains an interesting development as both DPO and IPO require pair preference data, whereas KTO can be applied to any dataset in which the response is evaluated positively or negatively.
We look forward to the new tools and techniques that will be developed in 2024!
