


Today we are excited to present our cutting-edge image generation and editing model, Gemini 2.5 Flash Image (aka Nano-Banana). With this update, you can blend multiple images into a single image, maintain character consistency in rich storytelling, use natural language to perform targeted transformations, and use Gemini’s world knowledge to generate and edit images.
When we first launched native image generation on Gemini 2.0 Flash earlier this year, you told us that you liked its low latency, cost-effectiveness and ease of use. But it also gave us feedback that we needed high quality images and stronger creative control.
This model is currently available from the Gemini API and from Google AI Studio for Developers and Vertex AI for Enterprise. The Gemini 2.5 flash images cost $30.00 per million output tokens, with each image 1290 output tokens ($0.039 per image). All other modalities regarding inputs and outputs follow Gemini 2.5 flash pricing.
Gemini 2.5 Flash Image in Action
To make Gemini 2.5 flash images even easier, we have significantly updated Google AI Studio’s “Build Mode” (including future updates). The example below not only allows you to quickly test the functionality of your model with a custom AI-powered app, but also allows you to remix and realize your ideas at a single prompt. Once you’re ready to share your built app, you can either deploy it from Google AI Studio or save your code to GitHub.
Try prompts like “Create an image editing app that lets users upload images and apply different filters” or choose one of our preset templates and remix them all for free!
Maintains character consistency
The fundamental challenge of image generation is to maintain the appearance of a character or object across multiple prompts and editing. You can place the same characters in different environments, show a single product from multiple angles in new settings, or generate consistent brand assets while saving subjects.
I built a template app in Google AI Studio (on top of that, easily customize the vibe code to create a vibe code), and demonstrated the consistency feature of the model’s characters.
Sorry, the browser does not support playing this video
(Sequence shortening)
Beyond character consistency, this model is also excellent at adhering to visual templates. Developers are exploring areas such as real estate list cards, uniform employee badges, and dynamic product mockups from all design templates, from dynamic product mockups across the catalog.

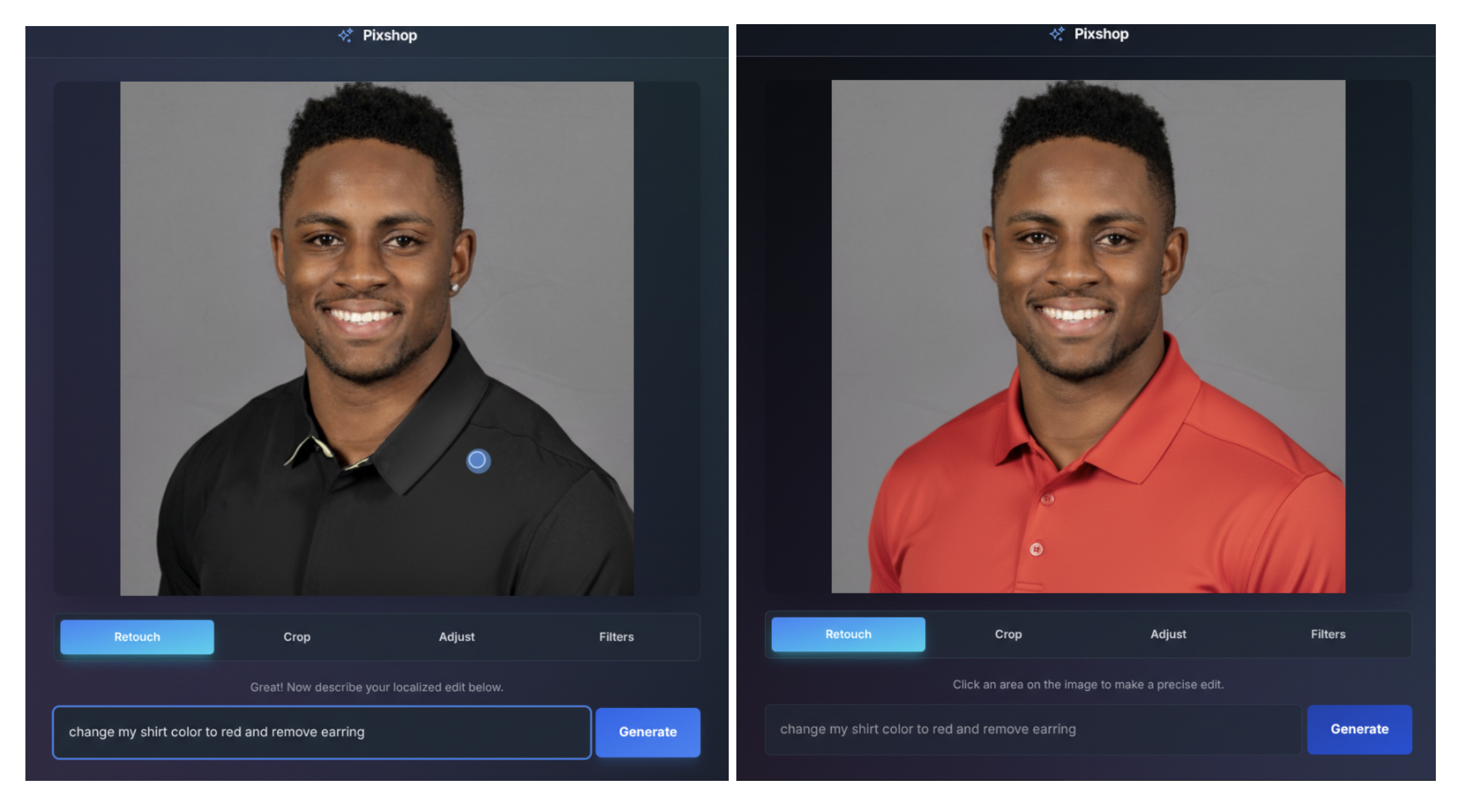
Prompt-based image editing
Gemini 2.5 flash images allow for targeted transformations and accurate local editing using natural language. For example, models can blur the background of images, remove stains from T-shirts, remove the entire person from the photo, change the subject’s pose, add color to the black and white photo, or recall it with a simple prompt.
To demonstrate that I’m performing these functions, I created a photo editing template app in AI Studio using both the UI and prompt-based controls.
Native world knowledge
Historically, image-generating models have excel in aesthetic images, but lacked a deep semantic understanding of the real world. In Gemini 2.5 Flash Image, models benefit from Gemini’s world knowledge and unlock new use cases.
To demonstrate this, I built a template app in Google AI Studio and turned a simple canvas into an interactive educational tutor. It introduces the ability of a model to read and understand hand-drawn diagrams, help with real-world questions, and follow complex editing procedures in one step.
Sorry, the browser does not support playing this video
(Example prompts and model results)
Multi-image fusion
Gemini 2.5 flash images can understand and merge multiple input images. You can put objects in the scene, stop rooms with color schemes and textures, or fuse images with a single prompt.
To showcase the fusion of multi-images, I built a template app with Google AI Studio. This allows you to quickly create new PhotoRealistic Fused images by dragging your product into a new scene.
Sorry, the browser does not support playing this video
(Sequence has been shortened)
Let’s start the building
Check out the developer documentation to get started with Gemini 2.5 Flash Image. This model is previewed today via Gemini API and Google AI Studio, but will remain stable over the next few weeks. All of the demo apps highlighted here are coded vibes in Google AI Studio, so you can remix and customize them at the prompts alone.
OpenRouter.ai partners with us to provide Gemini 2.5 Flash Images to 3M+ developers everywhere today. This is the first model of OpenRouter that can generate images.
We are also excited to partner with Fal.ai, the leading developer platform for generator media, to make Gemini 2.5 flash images available to the broader developer community.
All images created or edited with Gemini 2.5 Flash images contain invisible Synthid digital watermarks, which can be identified as AI generation or edited.
Import from Google from Genai to IO from Import Import bytesio client = genai.client() prompt = “Create a photo of a cat eating nano banana in a flashy restaurant under Gemini Constellation” image = yigms.open(‘/path/to/image.png’)respons = client.models.generii-2.5-flash-2.5-flash-5-flash-5-flash- contents = (prompt, image),) for part in response.candidates(0).content.parts:part.text is no None:print(part.text)elif part.inline_data is none:image = image.open(bytesio(part.inline_data.data)image.save
Python
We are actively working to improve de facto representations like long-form text rendering, more reliable character consistency, and fine details of images. Please continue to send feedback on the Developer Forum or on X.
Can’t wait to see what you build with Gemini 2.5 Flash Image!
