


Setfitabsa is an efficient technique for detecting feelings about a particular aspect of a text.
Aspect-based sentiment analysis (ABSA) is the task of detecting emotions towards a particular aspect of the text. For example, in the statement “This phone has a great screen, but the battery is too small,” the aspect terms are “screen” and “battery,” and the polarities of emotions towards them are positive and negative, respectively.
ABSA is widely used by organizations to extract valuable insights by analyzing customer feedback towards aspects of products or services in various domains. However, labeling training data in ABSA is a boring task due to the nature of manually identifying aspects within the training sample (token level).
Intel Labs and Hugging Face are excited to introduce SetFitabsa, a framework for small shot training for domain-specific ABSA models. Setfitabsa is competitive and outperforms generative models such as Llama2 and T5 even in fewer shot scenarios.
Compared to the LLM-based method, SetFitabsa offers two unique advantages:
No components prompt required: A small number of context learning using LLMS requires handcrafted prompts that are brittle, phrasing sensitive, and rely on user expertise. Setfitabsa fully distributes the prompts by generating rich embeddings directly from a few examples of labeled text.
Trained Speed: Setfitabsa requires only a handful of labeled training samples. Additionally, it uses a simple training data format to eliminate the need for specialized tagging tools. This makes the data labeling process faster and easier.
In this blog post, I will explain how SetFitabsa works and how to train your own models using the SetFit library. Let’s jump in!
How does it work?
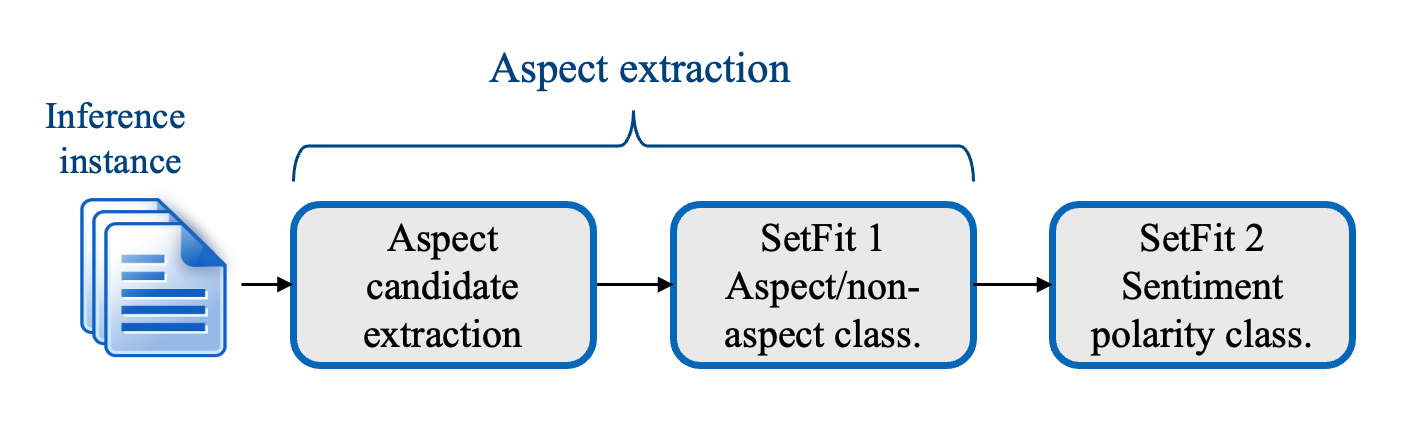
Setfitabsa’s 3-stage training process
Setfitabsa consists of three steps. The first step extracts aspect candidates from the text, the second step generates aspects by classifying aspect candidates as aspects or non-aspects, and the final step relates the polarity of sentiment to each extracted aspect. Steps 2 and 3 are based on the SetFit model.
training
1. Extracting aspect candidates
This work assumes that aspects that are usually characteristic of products and services are mostly nouns or noun compounds (strings of serial nouns). Use Spacey to tokenize and extract noun/noun compounds from sentences in the training set (less shots). Not all extracted noun/noun compounds are aspects, so we call them candidate aspects.
2. Aspect/non-aspect classification
Now that you can now have candidate aspects, you need to train your model to distinguish between nouns and nouns, which are aspects that are not aspects. For this purpose, training samples with aspect/aspect labels are required. This is done by considering aspects within the training set as true aspects, but other non-duplicate candidate aspects are considered non-aspect, so they are labeled as follows:
Training sentence: “Waiters are not friendly, but cream pasta is out of this world.” Tokenization: (Waiters, no, no, friendly, but cream, pasta, out, of, this, world,.) Extracted aspect candidates: (Waiters, friendly, friendly, pasta, of, this, this, world,.) Golden labels from training set, bioformat: o, o,. ) Generated aspect/non-aspect labels: (Waiter, no, no, friendly, but cream, pasta, of, this, world,.)
Now that all aspect candidates have been labeled, how do you use them to train candidate aspect classification models? In other words, how do you use SetFit, a statement classification framework, to classify individual tokens? Well, this is a trick. Each aspect candidate is concatenated with the entire training statement and creates a training instance using the following template:
aspect_candidate: training_sentence
Applying the template to the example above will generate three training instances. Two training instances generate two with true labels representing aspect training instances, one with false labels representing non-aspect training instances.
Text Label Waiter: The waiter is not friendly, but cream pasta is out of this world. 1 Cream Pasta: The waiter is not friendly, but cream pasta is out of this world. 1 World: The waiters aren’t friendly, but the cream pasta is out of this world. 0 … …
After generating the training instance, we use the power of SetFit to train several shot domain-specific binary classifiers to extract aspects from the input text review. This will be the first tweaked SetFit model.
3. Polarity classification of sentiment
Once the system extracts aspects from the text, it is necessary to associate the polarity of sentiment (e.g., positive, negative, or neutral) with each aspect. To this end, we use the second SetFit model to train in a similar way to the aspect extraction model, as shown in the following example:
Training sentence: “Waiters aren’t friendly, but cream pasta is out of this world.” Tokenization: (Waiters, no, no, friendly, but cream, pasta, of, of, this, world,.) Gold labels for training set: (neg, o, o, o, pos, pos, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o, o
Text Label Waiter: The waiter is not friendly, but cream pasta is out of this world. Negative Cream Pasta: The waiter isn’t friendly, but cream pasta is out of this world. POS … …
Note that, in contrast to aspect extraction models, this training set does not include non-aspects, as it is about classifying the polarity of sentiment into actual aspects.
Inferences undertaken
On inference, the test statement passes the extraction stage of the Spacey Aspect candidates, resulting in a test instance using the template Aspest_candidate:test_sentence. The non-aspects are then filtered by the aspect/non-aspect classifier. Finally, the extracted aspects are fed to an emotional polarity classifier that predicts emotional polarity per aspect.
In reality, this means that the model can receive regular text as input, and the aspects of the output and its feelings are:
Model input:
“Their dinner specials are amazing.”
Model output:
({‘Span’: ‘Dinner Special’, ‘Polarity’: ‘Positive’})
benchmark
Setfitabsa has been benchmarked against recent cutting edge research by research in AWS AI Labs and Salesforce AI using Finetune T5 and GPT2 using prompts. To obtain a more complete image, we compare the model with the llama-2 chat model using context learning. It uses the popular Laptop14 and Restaurant14 ABSA datasets from the Semantic Assessment Challenge 2014 (Semeval14). Setfitabsa is evaluated both in the intermediate task of aspect term extraction (SB1) and in the complete ABSA task of aspect extraction along with its emotional polarity prediction (SB1+SB2).
Comparison of model sizes
Model size (PARAMS) LLAMA-2-CHAT 7B T5-BASE 220M GPT2-BASE 124M GPT2-MEDIUM 355M SETFIT (MPNET) 2X 110M
For SB1 tasks, SetFitabsa is a 110m parameter, for SB2 it is a 110m parameter, for SB1+SB2 it is a 220M parameter.
Performance comparison
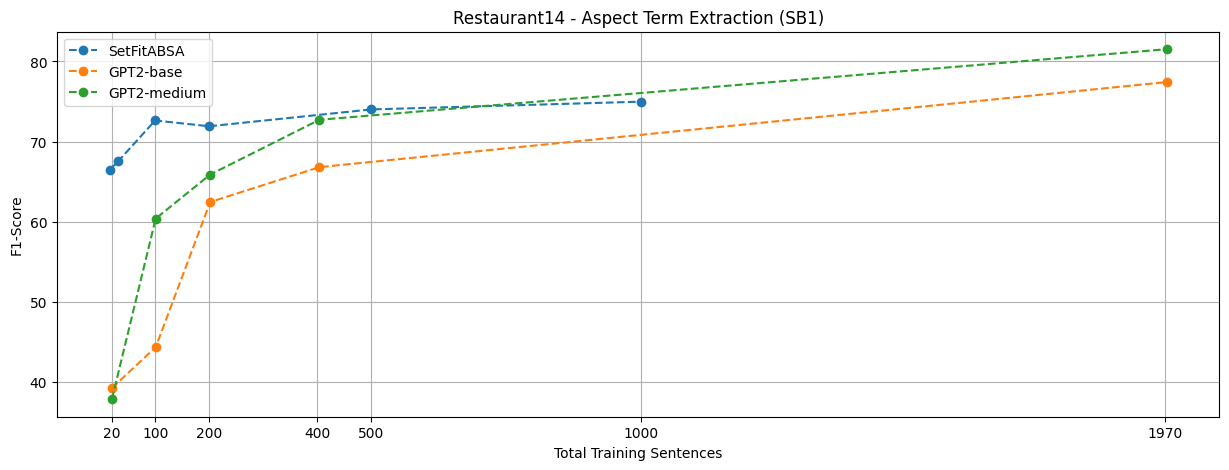
There is a clear advantage to Setfitabsa when it is twice as small as T5 and twice as small as GPT2 medium, but with a low number of training instances. Compared to the larger Llama 2, the performance is higher than PAR.
setfitabsa vs gpt2
Setfitabsa vs T5
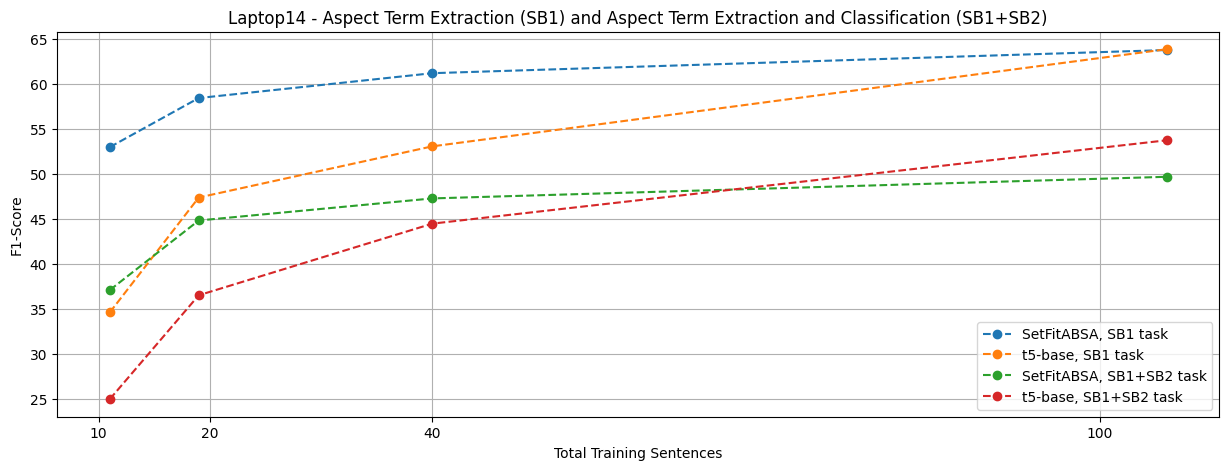
For a fair comparison, please note that we compared the dataset splits used at various baselines (GPT2, T5, etc.) accurately with SetFitabsa.
setfitabsa vs llama2
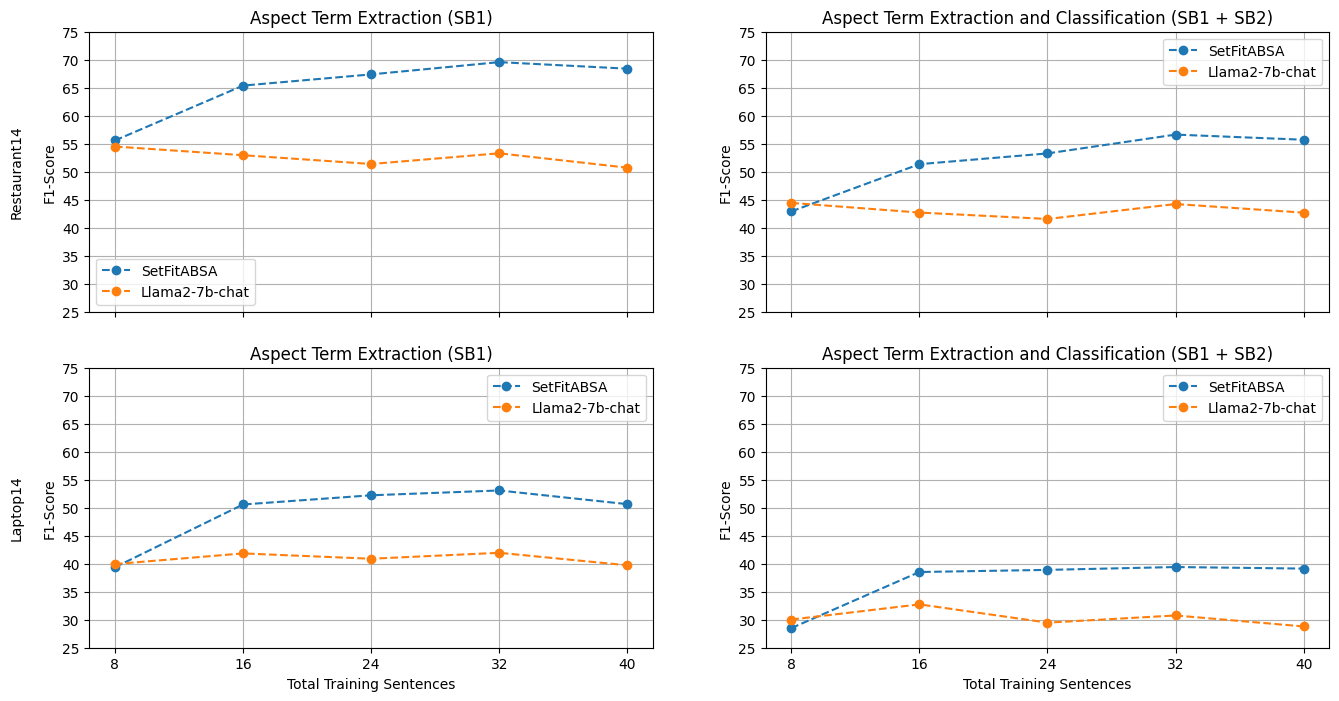
I noticed that increasing the number of in-context training samples in LLAMA2 did not improve performance. This phenomenon has been shown previously for ChatGpt and we believe it needs further investigation.
Train your own model
SetFitabsa is part of the SetFit framework. To train your ABSA model, start by installing SetFit with the ABSA option enabled.
python -m pip install -u “setfit(absa)”
Additionally, you will need to install the EN_CORE_WEB_LG Spacey model.
Download python -m Spacey download en_core_web_lg
Continue preparing your training set. The training set format is a data set with column text, spans, labels, and ordinals.
Text: A complete sentence or text containing sides. Span: Aspects from the full text. It can be multiple words. For example, “food.” Label: Polarity label that corresponds to aspect span. For example, “positive.” When tagging collected training data, the label name can be arbitrarily selected. Order: If aspect spans occur multiple times in text, this order represents the index of their occurrence. In many cases, this is only 0. This is because each side is usually only shown once in the input text.
For example, the training text “Restaurants with great food, but the worst service I’ve seen” contains two aspects, so add two rows to the training set table.
Text span label ordinal restaurant with great food, but worst service I’ve ever seen a restaurant with great food, but I’m not sure if the service is negative… … … … … … …
Once you have your training data set, you can create an ABSA trainer to run the training. Although the SetFit model is quite efficient to train, SetFitabsa includes two sequentially trained models, so it is recommended to use a GPU for training to maintain training time. For example, the following training script trains a complete SetFitabsa model in about 10 minutes using a free Google Colab T4 GPU:
from Dataset Import load_dataset
from setFit Import absatrainer,absamodel train_dataset =load_dataset(“Tomaarsen/setfit-absa-semeval-restaurants”split =“Train (: 128)”)Model = abasmodel.from_pretrained(“Cultural Transformer/Parafurasu-MPNET-Base-V2”) train = absatrainer (model, train_dataset = train_dataset) train.train()
that’s it! We trained domain-specific ABSA models. You can save the trained model to disk or upload it to the facehub of your hug. Note that the model contains two submodels, so each one is given its own path.
model.save_pretrained(
“Model/setfit-absa-model-aspect”,
“Model/setfit-absa-model-polarity”
)model.push_to_hub(
“Tomaarsen/SetFit-Absa-Paraphrase-Mpnet-base-v2-Restaurants-aspect”,
“Tomaarsen/setFit-ABSA-Paraphrase-MpNet-base-V2-Restaurants-Colality”
))
Now you can use the model trained for inference. Start by loading the model.
from setFit Import abasmodel model= abasmodel.from_pretrained(
“Tomaarsen/SetFit-Absa-Paraphrase-Mpnet-base-v2-Restaurants-aspect”,
“Tomaarsen/setFit-ABSA-Paraphrase-MpNet-base-V2-Restaurants-Colality”
))
Then use the prediction API to perform the inference. Input is a list of strings, each representing a text review.
preds = model.predict((()
“The best pizza outside of Italy and it’s really tasty.”,
“The food variations are great and the prices are absolutely fair.”,
“Unfortunately, if you expect a wait time and need to be very full, you’ll need to get a note with the number of waits.”
)))
printing(Preds)
For more information about training options, save and load models, and inference, see the SetFit documentation.
reference
Maria Pontiki, Dimitris Galanis, John Pavlopoulos, Harris Papageorgiou, Ion Androutsopoulos, Suresh Manandhar. 2014. SEMVAL-2014 Task 4: Aspect-based emotional analysis. Proceedings of the 8th International Workshop on Semantic Assessment (Semeval 2014), pages 27-35. Siddharth Varia, Shuai Wang, Kishaloy Halder, Robert Vacareanu, Miguel Ballesteros, Yassine Benajiba, Neha Anna John, Rishita Anubhai, Smaranda Muresan, Dan Roth, 2023 “Teaching Tuning for Small Shot Aspect-Based Sensation Analysis.” https://arxiv.org/abs/2210.06629 Ehsan Hosseini-Asl, Wenhao Liu, Caiming Xiong, 2022. https://arxiv.org/abs/2204.05356 Lewis Tunstall, Nils Reimers, Unso Eun Seo Jo, Luke Bates, Daniel Korat, Moshe Wasserblat, Oren Pereg, 2022. https://arxiv.org/abs/2209.11055
