


Three new benchmarks have recently been added to the Open LLM leaderboards, Winogrande, GSM8K and Drop, using the original implementation reproduced in Eleutherai Harness. The rough appearance of the drop score revealed something strange is happening. We went on a deep dive to understand what was going on.
Initial observation
A drop (separate inference on a paragraph) is an evaluation in which the model must extract relevant information from an English text paragraph before performing a separate inference procedure (for example, sort or count items to reach the correct answer; see the table below for an example). The metric used is the custom F1 and the exact match score.
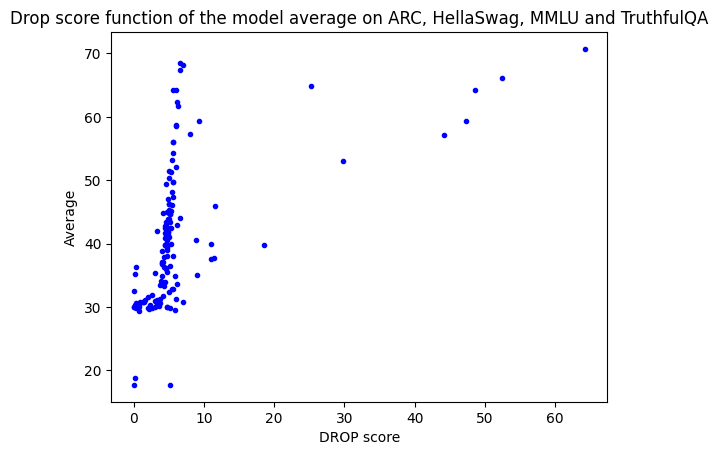
Three weeks ago, we added it to the open LLM leaderboard and observed that the F1 scores in the prerequisite models follow unexpected trends. When plotting drop scores against the original averages on the leaderboard (ARC, Hellaswag, Truthfulqa, MMLU). However, this was only true for a small number of models, with all other models having very low drop F1 scores below 10.
Normalized Interrogation
During the first deep dive of these surprising behavior, it was observed that the normalization step was not functioning as intended. In some cases, this normalization ignored the correct numerical answer when non-spaced white characters were directly connected (e.g., line return). Let’s take an example. The generation is 10\n\npassage. The 2011 census recorded a population of 1,001,360, with Gold’s answer being 10.
Normalization occurs in several steps, both in the production and in the gold:
Split into separators |, – or generate 10\n\npassage first sequence: no such separator is included, and therefore considered a single entity after this step. The first token to remove punctuation will be 10\n\npassage(: will be deleted). Any string that can be cast to float is considered a number, and is cast to float and re-converted to strings. 10\n\npassage remains the same as it cannot be cast to float, but gold 10 is 10.0. Other steps Many other normalization steps occur (deleting articles, deleting other white people, etc.), and the original example will be 10 passing populations in 2011.0.
However, the overall score is not calculated in a string, but in a bag of words (bows) extracted here (“record”, “population”, “passage”, “census”, “2011.0”, “1001360.0”, “10”}. As you can see, even if the model predicts the correct output, they don’t intersect!
In summary, if a number is followed by any kind of white space other than simple space, it will not pass the normalization of the number, so if it is a number it will not match gold! This initial issue could have ruined the score quite a bit, but obviously that wasn’t the only factor that made the drop score so low. I decided to do some more research.
I’ll jump into the results
Extending the investigation, Zeno friends joined us and embarked on a much more thorough investigation of the results. We looked into five models that represent the problems we noticed with drop scores. The Falcon-180B and Mistral-7B performed poorly compared to what the YI-34B and Tigerbot-70B had expected, when the YI-34B and Tigerbot-70B were performing with XGLM-5 dropping. middle.
If necessary, you can analyze the results in your Zeno project here!
The Zeno team found two more features in terms of functionality.
There is no single model that has obtained correct results at floating points.
At this point, we thought that both cases of failure were actually caused by the same route coefficient. As a stop word token (to end generation):
Floating point answers are systematically interrupted before generation becomes a completely high quality model. This matches a few shot prompt formats and generates the answer to the following questions\n\nplausible prompt: It will only stop after the actual answer.
We assumed that both of these issues could be fixed using \n instead of \n. Stop words as the end of generations.
Change the end of the generated token
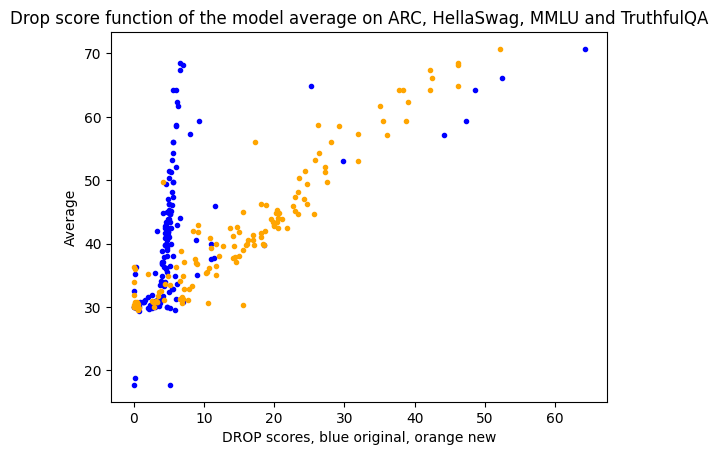
So we tried it! Available results were investigated using \n as the end of the generated token. If present, the generated response was split into the first \n and the score was recalculated. Note that this is merely an approximation of the correct results, as it does not correct answers too early. (For example, the answer to floating points) – But since all of them were affected by this issue, it doesn’t give any unfair advantage to any model. However, it’s the best thing you can do without rerunning the model (I wanted to post the community as soon as possible).
The results we got were: – splitting by \n correlates very well with other scores, which correlates with overall performance.
So, what’s next?
A simple calculation shows that rerunning a full evaluation of all models is extremely expensive (a full update took 8 years of GPU time, many of which took a drop), and we estimated how much it would cost to rerun only failed examples.
In 10% of cases, Gold’s answer is floating number (e.g. 12.25), and the model’s prediction starts with the correct beginning (in the example, 12), but is cut out with a. – These predictions would have actually been correct if generations continued. We definitely need to rerun them! Our estimates do not count generated sentences that either 40% of other generations (40% of other generations) end with numbers ruined by their normalization.
So, to get the correct results, you need to rerun a huge amount of GPU time, over 50% of the example. This time you need to make sure the implementation you are running is correct.
After discussing with the fantastic Eleutherai team (both Github and Internally) who guided the code and helped with the investigation, it became very clear that the implementation of LM Eval Harness follows the “official drop” code very strictly. So I made the decision to remove drops from the open LLM leaderboard until a new version occurred.
One take on this study is the value of having many of the community look into the benchmarks jointly to detect previously overlooked errors. Again, the power of open source, community and open shine’s development is that it allows for transparent investigation of the root causes of benchmark problems that have been there for years.
We hope that community interested members will join forces with academics working on drop assessments to modify both scoring and normalization. The dataset itself is very interesting and cool so I would like to be able to use it again. We recommend providing feedback on how to evaluate drops on this issue.
We would like to thank many community members for pointing out issues with drop scores. We would also like to thank Eleutherai Harness and the Zeno team for much help on this issue.
