


Potential diffusion governs and powers the generated AI audio, imageand video generation.
But what? diffusion?
Converts noise into coherent images or media.
From noise to media, diffusion improves the output image at each step.
But what? Subject diffusion?
It is the same as diffusion, but is applied to hiding objects instead of images. The latency is purified at each step.
aaaand ..What is it? Subject?
Compact data representation.
Potentiality represents the essence of an image or media, compressed into a smaller, more abstract space where the original media can be reconstructed.
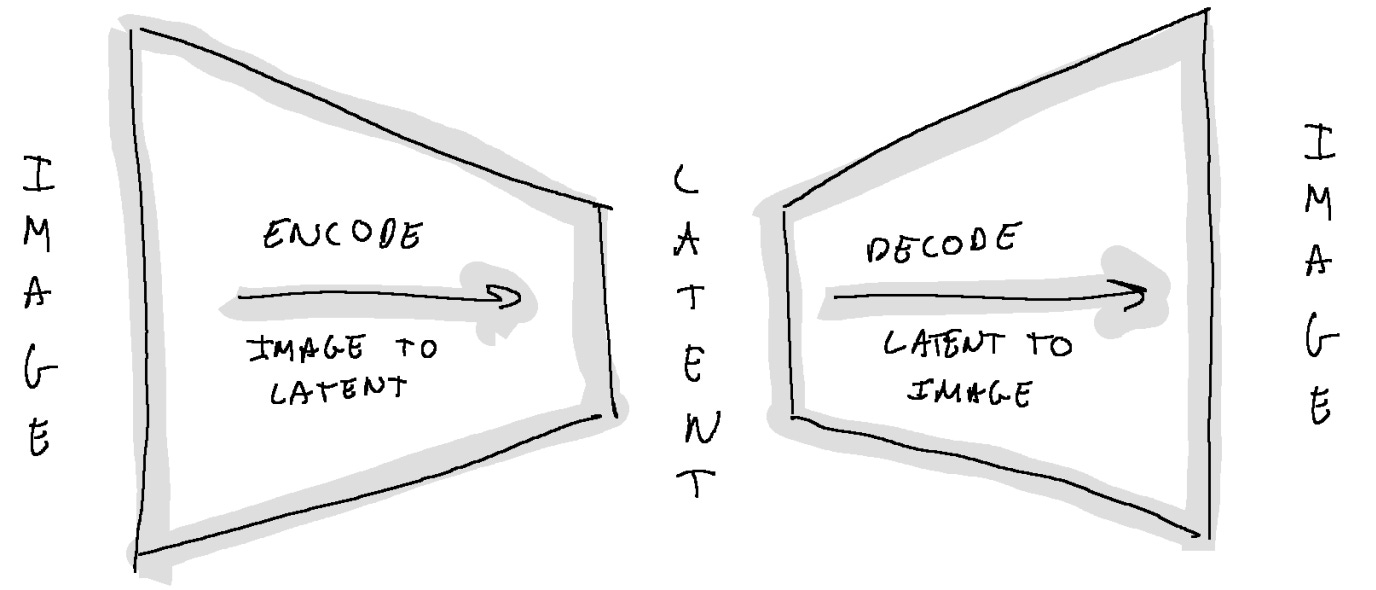
It works in compressed latent space rather than directly on the image, reducing computational load.
Faster. writer.
Although potential diffusion is currently widely used, GANS and autoregressive models are also important.
Generated enemy network (GANS) Use the “generator” to create content and “identifiers” to detect whether they are real or generated. “Generators” will improve hostilely in order to create better content and deceive “discriminators.”
Auto-Regresive Model Generates the following values in a sequence based on one step at a time, based on previous ones: Such models can work with raw media (pixels, waveform samples) or with potential representations.
2016: Wavenet Autoregressive modeling of the waveforms was introduced.
2019: Hostile Audio Synthesis GAN has been successfully applied to audio.
2020: Jukebox We introduced a potential autoregressive model with a transformer.
2022: Audio Lum We performed potential autoregressive modeling work.
2024: Stable audio Latent diffusion applied for efficient text to music and text and audio.
Autoregressive models are also popular in audio, along with potential diffusion.
But the potential spread is fast. And you can run the device. This allows you to (inspire a jockey) in a club with a track that doesn’t exist yet (as opposed to a “disc jockey”). No internet is required.
2014: Ian Goodfellow et al. We introduced GAN, which once dominated image generation.
2017: Progressive Gun Generate high resolution photos and realistic images.
2018: Vigan GAN has been enlarged for high quality class conditional image generation.
2021: Dall-E We introduced image generation from potential autoregressive text and temporarily led the field.
2022: Stable diffusionThe potential diffusion model enabled images from efficient text.
Since 2022, potential diffusion has dominated image generation. The stable, spreading open source model stimulates creative experiments like the QR code art below.

2022: image Generate high-resolution videos using cascaded diffusion models.
2023: Stable video Adapt stable diffusion to video generation.
2024: Sora Use (potential) diffusion transformers for video generation.
2024: Hunyuan It also uses potential diffusion transformers, but is open source.
2024: VEO 2 It is the latest video generation model, with no details on public technology.
AI video fields are emerging rapidly. In 2024, Sora took a major step towards cutting edge.
And includes some artists Shy kidsWe investigated the possibility of this VFX Workflow.
Disclaimer. The views expressed are myself and do not reflect the opinions or positions of my employer.
